
Intent Classification with BERT
Contents
Intent Classification with BERT#
This notebook demonstrates the fine-tuning of BERT to perform intent classification. Intent classification tries to map given instructions (sentence in natural language) to a set of predefined intents.
What you will learn#
Load data from csv and preprocess it for training and test
Load a BERT model from TensorFlow Hub
Build your own model by combining BERT with a classifier
Train your own model, fine-tuning BERT as part of that
Save your model and use it to recognize the intend of instructions
About BERT#
BERT and other Transformer encoder architectures have been shown to be successful on a variety of tasks in NLP (natural language processing). They compute vector-space representations of natural language that are suitable for use in deep learning models. The BERT family of models uses the Transformer encoder architecture to process each token of input text in the full context of all tokens before and after, hence the name: Bidirectional Encoder Representations from Transformers.
BERT models are usually pre-trained on a large corpus of text, then fine-tuned for specific tasks.
Setup#
# Required to preprocess text for BERT inputs
!pip install -q tensorflow-text==2.6.0
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
mtcnn 0.1.0 requires opencv-python>=4.1.0, but you have opencv-python 3.4.13.47 which is incompatible.
import os
#import shutil
import pandas as pd
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_text as text
import seaborn as sns
from pylab import rcParams
import matplotlib.pyplot as plt
tf.get_logger().setLevel('ERROR')
sns.set(style='whitegrid', palette='muted', font_scale=1.2)
HAPPY_COLORS_PALETTE = ["#01BEFE", "#FFDD00", "#FF7D00", "#FF006D", "#ADFF02", "#8F00FF"]
sns.set_palette(sns.color_palette(HAPPY_COLORS_PALETTE))
rcParams['figure.figsize'] = 12, 8
import warnings
warnings.filterwarnings("ignore")
Data Access#
The data contains various user queries categorized into seven intents. It is hosted on GitHub and is first presented in this paper. In the list below the classes and an example for each class is given:
class: SearchCreativeWork -example:play hell house songclass: GetWeather -example: is it windy in boston, mb right nowclass: BookRestaurant -example: book a restaurant for eight people in six yearsclass: PlayMusic -example: play the song little robin redbreastclass: AddToPlaylist -example: add step to me to the 50 clásicos playlistclass: RateBook -example: give 6 stars to of mice and menclass: SearchScreeningEvent -example: find fish story
Data can be downloaded from a Google Drive by applying gdown. In the following code cells the download is invoked only if the corresponding file, does not yet exist at the corresponding location.
datafolder="/Users/johannes/DataSets/IntentClassification/"
trainfile=datafolder+"train.csv"
testfile=datafolder+"test.csv"
validfile=datafolder+"valid.csv"
#!pip install gdown
if not os.path.exists(trainfile):
!gdown --id 1OlcvGWReJMuyYQuOZm149vHWwPtlboR6 --output /Users/johannes/DataSets/IntentClassification/train.csv
if not os.path.exists(validfile):
!gdown --id 1Oi5cRlTybuIF2Fl5Bfsr-KkqrXrdt77w --output /Users/johannes/DataSets/IntentClassification/valid.csv
if not os.path.exists(testfile):
!gdown --id 1ep9H6-HvhB4utJRLVcLzieWNUSG3P_uF --output /Users/johannes/DataSets/IntentClassification/test.csv
Next, the downloaded .csv-files for training, validation and test are imported into pandas dataframes:
traindf = pd.read_csv(trainfile)
validdf = pd.read_csv(validfile)
testdf = pd.read_csv(testfile)
traindf.head()
| text | intent | |
|---|---|---|
| 0 | listen to westbam alumb allergic on google music | PlayMusic |
| 1 | add step to me to the 50 clásicos playlist | AddToPlaylist |
| 2 | i give this current textbook a rating value of... | RateBook |
| 3 | play the song little robin redbreast | PlayMusic |
| 4 | please add iris dement to my playlist this is ... | AddToPlaylist |
Training data contains 13084 instructions:
traindf.shape
(13084, 2)
trainfeatures=traindf.copy()
trainlabels=trainfeatures.pop("intent")
trainfeatures=trainfeatures.values
Distribution of class-labels in training-data:
chart = sns.countplot(trainlabels, palette=HAPPY_COLORS_PALETTE)
plt.title("Number of texts per intent")
chart.set_xticklabels(chart.get_xticklabels(), rotation=30, horizontalalignment='right');
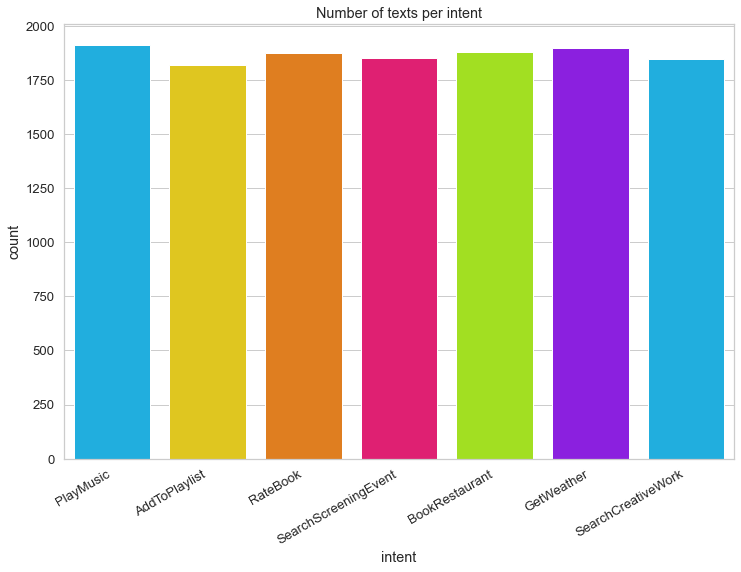
One-Hot-Encoding of class-labels:
from sklearn.preprocessing import LabelBinarizer
binarizer=LabelBinarizer()
trainlabels=binarizer.fit_transform(trainlabels.values)
trainlabels.shape
(13084, 7)
Preprocess test- and validation data in the same way as it has been done for training-data:
testfeatures=testdf.copy()
testlabels=testfeatures.pop("intent")
validfeatures=validdf.copy()
validlabels=validfeatures.pop("intent")
testfeatures=testfeatures.values
validfeatures=validfeatures.values
testlabels=binarizer.transform(testlabels.values)
validlabels=binarizer.transform(validlabels.values)
Loading models from TensorFlow Hub#
Here you can choose which BERT model you will load from TensorFlow Hub and fine-tune. There are multiple BERT models available.
BERT-Base, Uncased and seven more models with trained weights released by the original BERT authors.
Small BERTs have the same general architecture but fewer and/or smaller Transformer blocks, which lets you explore tradeoffs between speed, size and quality.
ALBERT: four different sizes of “A Lite BERT” that reduces model size (but not computation time) by sharing parameters between layers.
BERT Experts: eight models that all have the BERT-base architecture but offer a choice between different pre-training domains, to align more closely with the target task.
Electra has the same architecture as BERT (in three different sizes), but gets pre-trained as a discriminator in a set-up that resembles a Generative Adversarial Network (GAN).
BERT with Talking-Heads Attention and Gated GELU [base, large] has two improvements to the core of the Transformer architecture.
The model documentation on TensorFlow Hub has more details and references to the
research literature. Follow the links above, or click on the tfhub.dev URL
printed after the next cell execution.
The suggestion is to start with a Small BERT (with fewer parameters) since they are faster to fine-tune. If you like a small model but with higher accuracy, ALBERT might be your next option. If you want even better accuracy, choose one of the classic BERT sizes or their recent refinements like Electra, Talking Heads, or a BERT Expert.
Aside from the models available below, there are multiple versions of the models that are larger and can yield even better accuracy but they are too big to be fine-tuned on a single GPU. You will be able to do that on the Solve GLUE tasks using BERT on a TPU colab.
You’ll see in the code below that switching the tfhub.dev URL is enough to try any of these models, because all the differences between them are encapsulated in the SavedModels from TF Hub.
bert_model_name = 'small_bert/bert_en_uncased_L-8_H-512_A-8'
map_name_to_handle = {
'bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_L-12_H-768_A-12/3',
'bert_en_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_cased_L-12_H-768_A-12/3',
'bert_multi_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_multi_cased_L-12_H-768_A-12/3',
'small_bert/bert_en_uncased_L-2_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-128_A-2/1',
'small_bert/bert_en_uncased_L-2_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-256_A-4/1',
'small_bert/bert_en_uncased_L-2_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-512_A-8/1',
'small_bert/bert_en_uncased_L-2_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-768_A-12/1',
'small_bert/bert_en_uncased_L-4_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-128_A-2/1',
'small_bert/bert_en_uncased_L-4_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-256_A-4/1',
'small_bert/bert_en_uncased_L-4_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1',
'small_bert/bert_en_uncased_L-4_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-768_A-12/1',
'small_bert/bert_en_uncased_L-6_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-128_A-2/1',
'small_bert/bert_en_uncased_L-6_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-256_A-4/1',
'small_bert/bert_en_uncased_L-6_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-512_A-8/1',
'small_bert/bert_en_uncased_L-6_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-768_A-12/1',
'small_bert/bert_en_uncased_L-8_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-128_A-2/1',
'small_bert/bert_en_uncased_L-8_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-256_A-4/1',
'small_bert/bert_en_uncased_L-8_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-512_A-8/1',
'small_bert/bert_en_uncased_L-8_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-768_A-12/1',
'small_bert/bert_en_uncased_L-10_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-128_A-2/1',
'small_bert/bert_en_uncased_L-10_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-256_A-4/1',
'small_bert/bert_en_uncased_L-10_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-512_A-8/1',
'small_bert/bert_en_uncased_L-10_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-768_A-12/1',
'small_bert/bert_en_uncased_L-12_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-128_A-2/1',
'small_bert/bert_en_uncased_L-12_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-256_A-4/1',
'small_bert/bert_en_uncased_L-12_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-512_A-8/1',
'small_bert/bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-768_A-12/1',
'albert_en_base':
'https://tfhub.dev/tensorflow/albert_en_base/2',
'electra_small':
'https://tfhub.dev/google/electra_small/2',
'electra_base':
'https://tfhub.dev/google/electra_base/2',
'experts_pubmed':
'https://tfhub.dev/google/experts/bert/pubmed/2',
'experts_wiki_books':
'https://tfhub.dev/google/experts/bert/wiki_books/2',
'talking-heads_base':
'https://tfhub.dev/tensorflow/talkheads_ggelu_bert_en_base/1',
}
map_model_to_preprocess = {
'bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/2',
'bert_en_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_cased_preprocess/2',
'small_bert/bert_en_uncased_L-2_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/2',
'small_bert/bert_en_uncased_L-2_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/2',
'small_bert/bert_en_uncased_L-2_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/2',
'small_bert/bert_en_uncased_L-2_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/2',
'small_bert/bert_en_uncased_L-4_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/2',
'small_bert/bert_en_uncased_L-4_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/2',
'small_bert/bert_en_uncased_L-4_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/2',
'small_bert/bert_en_uncased_L-4_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/2',
'small_bert/bert_en_uncased_L-6_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/2',
'small_bert/bert_en_uncased_L-6_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/2',
'small_bert/bert_en_uncased_L-6_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/2',
'small_bert/bert_en_uncased_L-6_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/2',
'small_bert/bert_en_uncased_L-8_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/2',
'small_bert/bert_en_uncased_L-8_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/2',
'small_bert/bert_en_uncased_L-8_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/2',
'small_bert/bert_en_uncased_L-8_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/2',
'small_bert/bert_en_uncased_L-10_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/2',
'small_bert/bert_en_uncased_L-10_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/2',
'small_bert/bert_en_uncased_L-10_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/2',
'small_bert/bert_en_uncased_L-10_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/2',
'small_bert/bert_en_uncased_L-12_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/2',
'small_bert/bert_en_uncased_L-12_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/2',
'small_bert/bert_en_uncased_L-12_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/2',
'small_bert/bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/2',
'bert_multi_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_multi_cased_preprocess/2',
'albert_en_base':
'https://tfhub.dev/tensorflow/albert_en_preprocess/2',
'electra_small':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/2',
'electra_base':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/2',
'experts_pubmed':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/2',
'experts_wiki_books':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/2',
'talking-heads_base':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/2',
}
tfhub_handle_encoder = map_name_to_handle[bert_model_name]
tfhub_handle_preprocess = map_model_to_preprocess[bert_model_name]
print(f'BERT model selected : {tfhub_handle_encoder}')
print(f'Preprocess model auto-selected: {tfhub_handle_preprocess}')
BERT model selected : https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-512_A-8/1
Preprocess model auto-selected: https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/2
The preprocessing model#
Text inputs need to be transformed to numeric token ids and arranged in several Tensors before being input to BERT. TensorFlow Hub provides a matching preprocessing model for each of the BERT models discussed above, which implements this transformation using TF ops from the TF.text library. It is not necessary to run pure Python code outside your TensorFlow model to preprocess text.
The preprocessing model must be the one referenced by the documentation of the BERT model, which you can read at the URL printed above. For BERT models from the drop-down above, the preprocessing model is selected automatically.
Note: You will load the preprocessing model into a hub.KerasLayer to compose your fine-tuned model. This is the preferred API to load a TF2-style SavedModel from TF Hub into a Keras model.
bert_preprocess_model = hub.KerasLayer(tfhub_handle_preprocess)
Let’s try the preprocessing model on some text and see the output:
trainfeatures[0]
array(['listen to westbam alumb allergic on google music'], dtype=object)
text_test = trainfeatures[0]
text_preprocessed = bert_preprocess_model(text_test)
print(f'Keys : {list(text_preprocessed.keys())}')
print(f'Shape : {text_preprocessed["input_word_ids"].shape}')
print(f'Word Ids : {text_preprocessed["input_word_ids"][0, :12]}')
print(f'Input Mask : {text_preprocessed["input_mask"][0, :12]}')
print(f'Type Ids : {text_preprocessed["input_type_ids"][0, :12]}')
Keys : ['input_word_ids', 'input_mask', 'input_type_ids']
Shape : (1, 128)
Word Ids : [ 101 4952 2000 2225 3676 2213 2632 25438 27395 2006 8224 2189]
Input Mask : [1 1 1 1 1 1 1 1 1 1 1 1]
Type Ids : [0 0 0 0 0 0 0 0 0 0 0 0]
As can be seen, there are 3 outputs from the preprocessing that a BERT model would use (input_words_id, input_mask and input_type_ids).
Some other important points:
The input is truncated to 128 tokens. The number of tokens can be customized and you can see more details on the Solve GLUE tasks using BERT on a TPU colab.
The
input_type_idsonly have one value (0) because this is a single sentence input. For a multiple sentence input, it would have one number for each input.
Since this text preprocessor is a TensorFlow model, It can be included in your model directly.
Using the BERT model#
Before putting BERT into an own model, let’s take a look at its outputs. You will load it from TF Hub and see the returned values.
bert_model = hub.KerasLayer(tfhub_handle_encoder)
bert_results = bert_model(text_preprocessed)
print(f'Loaded BERT: {tfhub_handle_encoder}')
print(f'Pooled Outputs Shape:{bert_results["pooled_output"].shape}')
print(f'Pooled Outputs Values:{bert_results["pooled_output"][0, :12]}')
print(f'Sequence Outputs Shape:{bert_results["sequence_output"].shape}')
print(f'Sequence Outputs Values:{bert_results["sequence_output"][0, :12]}')
Loaded BERT: https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-512_A-8/1
Pooled Outputs Shape:(1, 512)
Pooled Outputs Values:[-0.0496942 -0.16525196 -0.9980706 -0.9327927 -0.6145213 -0.22613096
-0.9558851 -0.50678325 0.29122883 0.2631647 0.7982282 0.49405974]
Sequence Outputs Shape:(1, 128, 512)
Sequence Outputs Values:[[-0.10247643 0.2220486 0.5988388 ... -0.25584024 0.61985415
-0.0182253 ]
[ 0.45503587 -0.5723831 0.55420965 ... -0.28608802 1.3628978
0.91311985]
[ 0.42473745 0.29045242 0.82692915 ... 0.28371722 1.7948042
-0.36674204]
...
[-0.46153072 0.0282942 0.5167359 ... -0.1503543 1.4651562
0.6449581 ]
[ 0.71108186 1.0848472 0.66065186 ... 0.47941187 0.7233063
-0.08312234]
[ 0.3555895 -0.38904855 0.51018417 ... 0.19970977 0.86474466
0.12226923]]
The BERT models return a map with 3 important keys: pooled_output, sequence_output, encoder_outputs:
pooled_outputto represent each input sequence as a whole. The shape is[batch_size, H]. You can think of this as an embedding for the entire movie review.sequence_outputrepresents each input token in the context. The shape is[batch_size, seq_length, H]. You can think of this as a contextual embedding for every token in the movie review.encoder_outputsare the intermediate activations of theLTransformer blocks.outputs["encoder_outputs"][i]is a Tensor of shape[batch_size, seq_length, 1024]with the outputs of the i-th Transformer block, for0 <= i < L. The last value of the list is equal tosequence_output.
For the fine-tuning you are going to use the pooled_output array.
Define your model#
You will create a very simple fine-tuned model, with the preprocessing model, the selected BERT model, one Dense and a Dropout layer.
Note: for more information about the base model’s input and output you can use just follow the model’s url for documentation. Here specifically you don’t need to worry about it because the preprocessing model will take care of that for you.
def build_classifier_model():
text_input = tf.keras.layers.Input(shape=(), dtype=tf.string, name='text')
preprocessing_layer = hub.KerasLayer(tfhub_handle_preprocess, name='preprocessing')
encoder_inputs = preprocessing_layer(text_input)
encoder = hub.KerasLayer(tfhub_handle_encoder, trainable=True, name='BERT_encoder')
outputs = encoder(encoder_inputs)
net = outputs['pooled_output']
net = tf.keras.layers.Dropout(0.1)(net)
net = tf.keras.layers.Dense(7, activation=None, name='classifier')(net)
return tf.keras.Model(text_input, net)
Let’s check that the model runs with the output of the preprocessing model.
classifier_model = build_classifier_model()
bert_raw_result = classifier_model(tf.constant(trainfeatures[0]))
print(tf.keras.activations.softmax(bert_raw_result))
tf.Tensor(
[[0.51704866 0.09932686 0.23939744 0.0246855 0.02893808 0.04027716
0.05032637]], shape=(1, 7), dtype=float32)
The output is meaningless, of course, because the model has not been trained yet.
Let’s take a look at the model’s structure.
classifier_model.summary()
Model: "model_1"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
text (InputLayer) [(None,)] 0
__________________________________________________________________________________________________
preprocessing (KerasLayer) {'input_word_ids': ( 0 text[0][0]
__________________________________________________________________________________________________
BERT_encoder (KerasLayer) {'default': (None, 5 41373185 preprocessing[0][0]
preprocessing[0][1]
preprocessing[0][2]
__________________________________________________________________________________________________
dropout_1 (Dropout) (None, 512) 0 BERT_encoder[0][9]
__________________________________________________________________________________________________
classifier (Dense) (None, 7) 3591 dropout_1[0][0]
==================================================================================================
Total params: 41,376,776
Trainable params: 41,376,775
Non-trainable params: 1
__________________________________________________________________________________________________
Model training#
You now have all the pieces to train a model, including the preprocessing module, BERT encoder, data, and classifier.
Since this is a non-binary classification problem and the model outputs probabilities, you’ll use losses.CategoricalCrossentropy loss function.
loss = tf.keras.losses.CategoricalCrossentropy(from_logits=True)
metrics = tf.metrics.CategoricalAccuracy()
Loading the BERT model and training#
Using the classifier_model you created earlier, you can compile the model with the loss, metric and optimizer.
epochs=5
optimizer=tf.keras.optimizers.Adam(1e-5)
classifier_model.compile(optimizer=optimizer,
loss=loss,
metrics=metrics)
Note: training time will vary depending on the complexity of the BERT model you have selected.
print(f'Training model with {tfhub_handle_encoder}')
history = classifier_model.fit(x=trainfeatures,y=trainlabels,
validation_data=(validfeatures,validlabels),
batch_size=32,
epochs=epochs)
Training model with https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-512_A-8/1
Epoch 1/5
409/409 [==============================] - 1866s 5s/step - loss: 0.3508 - categorical_accuracy: 0.8992 - val_loss: 0.0508 - val_categorical_accuracy: 0.9857
Epoch 2/5
409/409 [==============================] - 1813s 4s/step - loss: 0.0547 - categorical_accuracy: 0.9860 - val_loss: 0.0331 - val_categorical_accuracy: 0.9857
Epoch 3/5
409/409 [==============================] - 1812s 4s/step - loss: 0.0342 - categorical_accuracy: 0.9906 - val_loss: 0.0365 - val_categorical_accuracy: 0.9886
Epoch 4/5
409/409 [==============================] - 1780s 4s/step - loss: 0.0247 - categorical_accuracy: 0.9928 - val_loss: 0.0438 - val_categorical_accuracy: 0.9871
Epoch 5/5
409/409 [==============================] - 1811s 4s/step - loss: 0.0177 - categorical_accuracy: 0.9944 - val_loss: 0.0408 - val_categorical_accuracy: 0.9857
Evaluate the model#
Let’s see how the model performs. Two values will be returned. Loss (a number which represents the error, lower values are better), and accuracy.
loss, accuracy = classifier_model.evaluate(testfeatures,testlabels)
print(f'Loss: {loss}')
print(f'Accuracy: {accuracy}')
22/22 [==============================] - 34s 1s/step - loss: 0.0856 - categorical_accuracy: 0.9743
Loss: 0.08561959117650986
Accuracy: 0.9742857217788696
Plot the accuracy and loss over time#
Based on the History object returned by model.fit(). You can plot the training and validation loss for comparison, as well as the training and validation accuracy:
history_dict = history.history
print(history_dict.keys())
acc = history_dict['categorical_accuracy']
val_acc = history_dict['val_categorical_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
fig = plt.figure(figsize=(10, 8))
fig.tight_layout()
plt.subplot(2, 1, 1)
# "bo" is for "blue dot"
plt.plot(epochs, loss, 'r', label='Training loss')
# b is for "solid blue line"
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.grid(True)
# plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.subplot(2, 1, 2)
plt.plot(epochs, acc, 'r', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.grid(True)
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
dict_keys(['loss', 'categorical_accuracy', 'val_loss', 'val_categorical_accuracy'])
<matplotlib.legend.Legend at 0x7fca48e9a790>
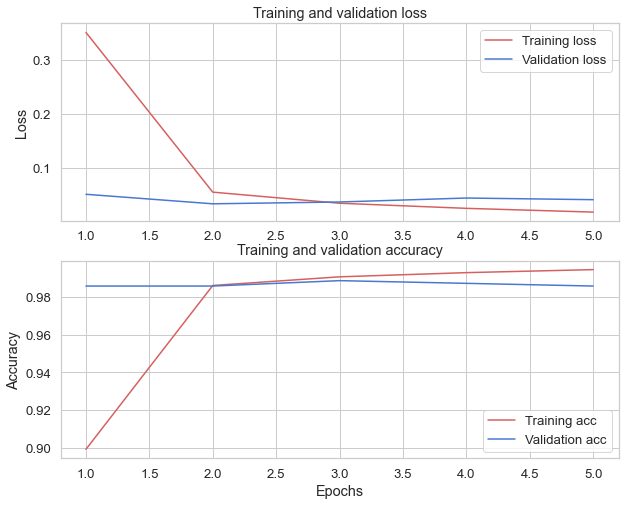
In this plot, the red lines represents the training loss and accuracy, and the blue lines are the validation loss and accuracy.
Classifying arbitrary instructions:
def print_my_examples(inputs, results):
result_for_printing = \
[f'input: {inputs[i]:<30} : estimated intent: {results[i]}'
for i in range(len(inputs))]
print(*result_for_printing, sep='\n')
print()
examples = [
'play a song from U2', # this is the same sentence tried earlier
'Will it rain tomorrow',
'I like to hear greatist hits from beastie boys',
'I like to book a table for 3 persons',
'5 stars for machines like me'
]
results = tf.nn.softmax(classifier_model(tf.constant(examples)))
binarizer.classes_
array(['AddToPlaylist', 'BookRestaurant', 'GetWeather', 'PlayMusic',
'RateBook', 'SearchCreativeWork', 'SearchScreeningEvent'],
dtype='<U20')
intents=binarizer.inverse_transform(results.numpy())
print_my_examples(examples, intents)
input: play a song from U2 : estimated intent: PlayMusic
input: Will it rain tomorrow : estimated intent: GetWeather
input: I like to hear greatist hits from beastie boys : estimated intent: PlayMusic
input: I like to book a table for 3 persons : estimated intent: BookRestaurant
input: 5 stars for machines like me : estimated intent: RateBook