
DCGAN Keras Implementation
Contents
DCGAN Keras Implementation#
Author: Johannes Maucher
Last Update: 04.11.2021
In this notebook a GAN is designed, which learns to generate handwritten numbers between 0 and 9, like the ones, given in the MNIST dataset. In this case the real data is the MNIST dataset, which contains 70000 greyscale images of size 28x28, 7000 images for each of the 10 digits.
The Discriminator model is just a binary classifier, whose task is to distinguish fake, from real images. The fake images are produced by the Generator model. At it’s input the Generator model receives 1-dimensional vectors of length 100, whose components are uniformly distributed random float-values between -1 and 1. The discriminator model is learned such that the cross-entropy-loss for discrimating real from fake images is minimized by Stochastic Gradient Descent (SGD). The Generator model is learned such that the generated fake data is classified as real-data by the discriminator.
Below a Deep Convolutional GAN (DCGAN) as introduced in A. Radford and L. Metz: Unsupervised Representation Learning with Deep Convolutional GANs is implemented. This type of GAN applies a Convolutional Neural Net (CNN) for the Generator- and the Discriminator model.
#!pip install tqdm
import tensorflow.compat.v1.keras.backend as K # see https://stackoverflow.com/questions/61056781/typeerror-tensor-is-unhashable-instead-use-tensor-ref-as-the-key-in-keras
import tensorflow as tf
tf.compat.v1.disable_eager_execution()
from keras.datasets import mnist
from keras.models import Model, Sequential
from tensorflow.keras.layers import *
from tensorflow.keras.optimizers import Adam
from tqdm import tqdm #this package is used to show progress in training loops
from tensorflow.keras.layers import LeakyReLU
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
The MNIST-handwritten digits dataset is available in the Keras datasets module and can be accessed as follows:
(X_train, Y_train), (X_test, Y_test) = mnist.load_data()
X_train.shape, Y_train.shape, X_test.shape, Y_test.shape
((60000, 28, 28), (60000,), (10000, 28, 28), (10000,))
X_train = X_train.reshape(X_train.shape[0], 28, 28, 1)
X_test = X_test.reshape(X_test.shape[0], 28, 28, 1)
print(X_train.shape)
print(X_test.shape)
X_train = X_train.astype('float32')
print(X_train[0,:,:,0])
(60000, 28, 28, 1)
(10000, 28, 28, 1)
[[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 3. 18.
18. 18. 126. 136. 175. 26. 166. 255. 247. 127. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 30. 36. 94. 154. 170. 253.
253. 253. 253. 253. 225. 172. 253. 242. 195. 64. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 49. 238. 253. 253. 253. 253. 253.
253. 253. 253. 251. 93. 82. 82. 56. 39. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 18. 219. 253. 253. 253. 253. 253.
198. 182. 247. 241. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 80. 156. 107. 253. 253. 205.
11. 0. 43. 154. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 14. 1. 154. 253. 90.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 139. 253. 190.
2. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 11. 190. 253.
70. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 35. 241.
225. 160. 108. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 81.
240. 253. 253. 119. 25. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
45. 186. 253. 253. 150. 27. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 16. 93. 252. 253. 187. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 249. 253. 249. 64. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
46. 130. 183. 253. 253. 207. 2. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 39. 148.
229. 253. 253. 253. 250. 182. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 24. 114. 221. 253.
253. 253. 253. 201. 78. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 23. 66. 213. 253. 253. 253.
253. 198. 81. 2. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 18. 171. 219. 253. 253. 253. 253. 195.
80. 9. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 55. 172. 226. 253. 253. 253. 253. 244. 133. 11.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 136. 253. 253. 253. 212. 135. 132. 16. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]]
The values of all input-images range from 0 to 255. Next, a rescaling to the range \([-1,1]\) is performed. This is necesarry, because the output-layer of the Generator model applies a tanh-activation, which has a value rane of \([-1,1]\).
X_train = (X_train - 127.5) / 127.5
print(X_train[0,:,:,0])
[[-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. ]
[-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. ]
[-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. ]
[-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. ]
[-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. ]
[-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1.
-0.9764706 -0.85882354 -0.85882354 -0.85882354 -0.01176471 0.06666667
0.37254903 -0.79607844 0.3019608 1. 0.9372549 -0.00392157
-1. -1. -1. -1. ]
[-1. -1. -1. -1. -1. -1.
-1. -1. -0.7647059 -0.7176471 -0.2627451 0.20784314
0.33333334 0.9843137 0.9843137 0.9843137 0.9843137 0.9843137
0.7647059 0.34901962 0.9843137 0.8980392 0.5294118 -0.49803922
-1. -1. -1. -1. ]
[-1. -1. -1. -1. -1. -1.
-1. -0.6156863 0.8666667 0.9843137 0.9843137 0.9843137
0.9843137 0.9843137 0.9843137 0.9843137 0.9843137 0.96862745
-0.27058825 -0.35686275 -0.35686275 -0.56078434 -0.69411767 -1.
-1. -1. -1. -1. ]
[-1. -1. -1. -1. -1. -1.
-1. -0.85882354 0.7176471 0.9843137 0.9843137 0.9843137
0.9843137 0.9843137 0.5529412 0.42745098 0.9372549 0.8901961
-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. ]
[-1. -1. -1. -1. -1. -1.
-1. -1. -0.37254903 0.22352941 -0.16078432 0.9843137
0.9843137 0.60784316 -0.9137255 -1. -0.6627451 0.20784314
-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. ]
[-1. -1. -1. -1. -1. -1.
-1. -1. -1. -0.8901961 -0.99215686 0.20784314
0.9843137 -0.29411766 -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. ]
[-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. 0.09019608
0.9843137 0.49019608 -0.9843137 -1. -1. -1.
-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. ]
[-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. -0.9137255
0.49019608 0.9843137 -0.4509804 -1. -1. -1.
-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. ]
[-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1.
-0.7254902 0.8901961 0.7647059 0.25490198 -0.15294118 -0.99215686
-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. ]
[-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1.
-1. -0.3647059 0.88235295 0.9843137 0.9843137 -0.06666667
-0.8039216 -1. -1. -1. -1. -1.
-1. -1. -1. -1. ]
[-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1.
-1. -1. -0.64705884 0.45882353 0.9843137 0.9843137
0.1764706 -0.7882353 -1. -1. -1. -1.
-1. -1. -1. -1. ]
[-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1.
-1. -1. -1. -0.8745098 -0.27058825 0.9764706
0.9843137 0.46666667 -1. -1. -1. -1.
-1. -1. -1. -1. ]
[-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. 0.9529412
0.9843137 0.9529412 -0.49803922 -1. -1. -1.
-1. -1. -1. -1. ]
[-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1.
-1. -1. -0.6392157 0.01960784 0.43529412 0.9843137
0.9843137 0.62352943 -0.9843137 -1. -1. -1.
-1. -1. -1. -1. ]
[-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1.
-0.69411767 0.16078432 0.79607844 0.9843137 0.9843137 0.9843137
0.9607843 0.42745098 -1. -1. -1. -1.
-1. -1. -1. -1. ]
[-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -0.8117647 -0.10588235
0.73333335 0.9843137 0.9843137 0.9843137 0.9843137 0.5764706
-0.3882353 -1. -1. -1. -1. -1.
-1. -1. -1. -1. ]
[-1. -1. -1. -1. -1. -1.
-1. -1. -0.81960785 -0.48235294 0.67058825 0.9843137
0.9843137 0.9843137 0.9843137 0.5529412 -0.3647059 -0.9843137
-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. ]
[-1. -1. -1. -1. -1. -1.
-0.85882354 0.34117648 0.7176471 0.9843137 0.9843137 0.9843137
0.9843137 0.5294118 -0.37254903 -0.92941177 -1. -1.
-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. ]
[-1. -1. -1. -1. -0.5686275 0.34901962
0.77254903 0.9843137 0.9843137 0.9843137 0.9843137 0.9137255
0.04313726 -0.9137255 -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. ]
[-1. -1. -1. -1. 0.06666667 0.9843137
0.9843137 0.9843137 0.6627451 0.05882353 0.03529412 -0.8745098
-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. ]
[-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. ]
[-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. ]
[-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. ]]
The first 9 real images in the training dataset are plotted below:
#plt.subplot(3,3,1)
for i in range (9):
plt.subplot(3,3,i+1)
plt.imshow(X_train[i+1, :, :, 0], cmap='gray')

Generator Model#
The Generator model receives 1-dimensional vectors of length 100 with uniformly distributed float values from -1 to 1 at it’s input. The first layer is a dense layer with 128x7x7 neurons. The output of this dense layer is reshaped into 128 channels, each of size 7x7. Using a deconvolution filter of size 5x5 (realized by an UpSampling2D-layer, followed by a Conv2D-layer) 64 channels of size 14x14 are generated in the next layer. Finally, these 64 channels are processed by another deconvolution layer with filters of size 5x5 into a single-channel output of size 28x28.
In between layers, batch normalization stabilizes learning. The activation function after the dense- and the first deconvolution-layer is a LeakyReLU. The output deconvolution-layer applies tanh- activation.
generator = Sequential([
Dense(128*7*7, input_dim=100),
LeakyReLU(0.2),
BatchNormalization(),
Reshape((7,7,128)),
UpSampling2D(),
Conv2D(64, (5, 5), padding='same'),
LeakyReLU(0.2),
BatchNormalization(),
UpSampling2D(),
Conv2D(1, (5, 5), padding='same', activation='tanh')
])
WARNING:tensorflow:From /Users/johannes/opt/anaconda3/envs/books/lib/python3.8/site-packages/keras/layers/normalization/batch_normalization.py:520: _colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.
Instructions for updating:
Colocations handled automatically by placer.
generator.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 6272) 633472
_________________________________________________________________
leaky_re_lu (LeakyReLU) (None, 6272) 0
_________________________________________________________________
batch_normalization (BatchNo (None, 6272) 25088
_________________________________________________________________
reshape (Reshape) (None, 7, 7, 128) 0
_________________________________________________________________
up_sampling2d (UpSampling2D) (None, 14, 14, 128) 0
_________________________________________________________________
conv2d (Conv2D) (None, 14, 14, 64) 204864
_________________________________________________________________
leaky_re_lu_1 (LeakyReLU) (None, 14, 14, 64) 0
_________________________________________________________________
batch_normalization_1 (Batch (None, 14, 14, 64) 256
_________________________________________________________________
up_sampling2d_1 (UpSampling2 (None, 28, 28, 64) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 28, 28, 1) 1601
=================================================================
Total params: 865,281
Trainable params: 852,609
Non-trainable params: 12,672
_________________________________________________________________
Discriminator Model#
The discriminator is also a CNN. For this experiment on the MNIST dataset, the input is an image (single channel) of size 28x28. The sigmoid output is an indicator for the probability that the input is a real image. I.e. if the output value is close to 1, the input is likely a real image, if the output is close to 0, the input is likely a fake. The first convolution layer applies 5x5 filters in order to calculate 64 features. The second convolution layer applies 5x5 filters to the 64 input channels and calculates 128 feature maps. The last dense layer has a single neuron with a sigmoid activation for binary classification.
The difference from a typical CNN is the absence of max-pooling in between layers. Instead, a strided convolution is used for downsampling. The activation function used in each CNN layer is a leaky ReLU. A dropout of 0.3 between layers is used to prevent overfitting and memorization.
discriminator = Sequential([
Conv2D(64, (5, 5), strides=(2,2), input_shape=(28,28,1), padding='same'),
LeakyReLU(0.2),
Dropout(0.3),
Conv2D(128, (5, 5), strides=(2,2), padding='same'),
LeakyReLU(0.2),
Dropout(0.3),
Flatten(),
Dense(1, activation='sigmoid')
])
discriminator.summary()
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_2 (Conv2D) (None, 14, 14, 64) 1664
_________________________________________________________________
leaky_re_lu_2 (LeakyReLU) (None, 14, 14, 64) 0
_________________________________________________________________
dropout (Dropout) (None, 14, 14, 64) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 7, 7, 128) 204928
_________________________________________________________________
leaky_re_lu_3 (LeakyReLU) (None, 7, 7, 128) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 7, 7, 128) 0
_________________________________________________________________
flatten (Flatten) (None, 6272) 0
_________________________________________________________________
dense_1 (Dense) (None, 1) 6273
=================================================================
Total params: 212,865
Trainable params: 212,865
Non-trainable params: 0
_________________________________________________________________
Next for the Generator- and the Discriminator the training algorithm is defined. Both models are trained by minimizing the binary cross-entropy loss. For both models the Adam algorithm is applied. In contrast to standard SGD, Adam applies individual learning-rates for each learnable parameter and adpats these learning-rates individually during training.
generator.compile(loss='binary_crossentropy', optimizer=Adam())
discriminator.compile(loss='binary_crossentropy', optimizer=Adam())
Build GAN by combining Generator and Discriminator#
Now, since Generator- and Discriminator models are defined, the overall adversarial model can be build, by simply stacking these models together. The output of the generator is passed to the input of the discriminator:
discriminator.trainable = False
ganInput = Input(shape=(100,))
x = generator(ganInput)
ganOutput = discriminator(x)
gan = Model(inputs=ganInput, outputs=ganOutput)
gan.compile(loss='binary_crossentropy', optimizer=Adam())
gan.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 100)] 0
_________________________________________________________________
sequential (Sequential) (None, 28, 28, 1) 865281
_________________________________________________________________
sequential_1 (Sequential) (None, 1) 212865
=================================================================
Total params: 1,078,146
Trainable params: 852,609
Non-trainable params: 225,537
_________________________________________________________________
Train GAN#
Finally, a function train() is implemented, which defines the overall training process. The flow-chart of this function is depicted below:
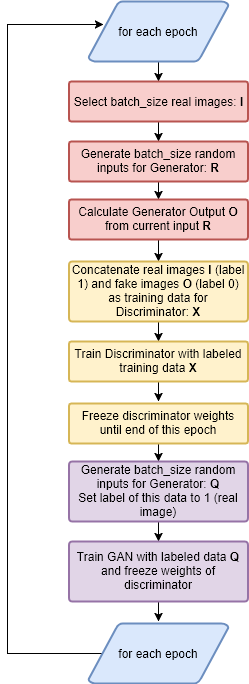
def train(epoch=10, batch_size=128):
batch_count = X_train.shape[0] // batch_size
for i in range(epoch):
for j in tqdm(range(batch_count)):
# Random input for the generator
noise_input = np.random.rand(batch_size, 100)
# select batchsize random images from X_train
# these are the real images that will be passed to the discriminator
image_batch = X_train[np.random.randint(0, X_train.shape[0], size=batch_size)]
# Predictions from the generator:
predictions = generator.predict(noise_input, batch_size=batch_size)
# the discriminator takes in the real images and the generated images
X = np.concatenate([predictions, image_batch])
# labels for the discriminator
y_discriminator = [0]*batch_size + [1]*batch_size
# train the discriminator
discriminator.trainable = True
discriminator.train_on_batch(X, y_discriminator)
# train the generator
noise_input = np.random.rand(batch_size, 100)
y_generator = [1]*batch_size
discriminator.trainable = False
gan.train_on_batch(noise_input, y_generator)
Train for 30 epochs. Depending on your hardware this process may take a long time. In my experiments on CPU about 20min per epoch and on GPU 12-15sec per epoch.
train(30, 128)
Save the weights, learned after these 30 epochs.
generator.save_weights('gen_30_scaled_images.h5')
discriminator.save_weights('dis_30_scaled_images.h5')
Start from the weight learned in 30 epochs and continue training for another 20 epochs:
train(30, 128)
100%|██████████| 468/468 [00:11<00:00, 40.27it/s]
100%|██████████| 468/468 [00:11<00:00, 40.41it/s]
100%|██████████| 468/468 [00:11<00:00, 39.83it/s]
100%|██████████| 468/468 [00:11<00:00, 39.13it/s]
100%|██████████| 468/468 [00:12<00:00, 38.76it/s]
100%|██████████| 468/468 [00:12<00:00, 38.66it/s]
100%|██████████| 468/468 [00:12<00:00, 38.71it/s]
100%|██████████| 468/468 [00:12<00:00, 38.61it/s]
100%|██████████| 468/468 [00:12<00:00, 38.81it/s]
100%|██████████| 468/468 [00:12<00:00, 37.92it/s]
100%|██████████| 468/468 [00:12<00:00, 38.63it/s]
100%|██████████| 468/468 [00:12<00:00, 38.84it/s]
100%|██████████| 468/468 [00:12<00:00, 38.52it/s]
100%|██████████| 468/468 [00:12<00:00, 38.68it/s]
100%|██████████| 468/468 [00:12<00:00, 38.46it/s]
100%|██████████| 468/468 [00:12<00:00, 38.54it/s]
100%|██████████| 468/468 [00:12<00:00, 38.62it/s]
100%|██████████| 468/468 [00:12<00:00, 38.56it/s]
100%|██████████| 468/468 [00:12<00:00, 38.56it/s]
100%|██████████| 468/468 [00:12<00:00, 38.10it/s]
100%|██████████| 468/468 [00:12<00:00, 38.54it/s]
100%|██████████| 468/468 [00:12<00:00, 37.98it/s]
100%|██████████| 468/468 [00:12<00:00, 38.64it/s]
100%|██████████| 468/468 [00:12<00:00, 38.65it/s]
100%|██████████| 468/468 [00:12<00:00, 38.68it/s]
100%|██████████| 468/468 [00:12<00:00, 38.52it/s]
100%|██████████| 468/468 [00:12<00:00, 38.68it/s]
100%|██████████| 468/468 [00:12<00:00, 38.47it/s]
100%|██████████| 468/468 [00:12<00:00, 38.92it/s]
100%|██████████| 468/468 [00:12<00:00, 38.43it/s]
Save the weights, learned after 60 epochs:
generator.save_weights('gen_60_scaled_images.h5')
discriminator.save_weights('dis_60_scaled_images.h5')
Generate new numbers from GAN#
GAN learned over 30 epochs#
Load the learned weights and apply them for generating fake images:
generator.load_weights('gen_30_scaled_images.h5')
discriminator.load_weights('dis_30_scaled_images.h5')
def plot_output():
try_input = np.random.rand(100, 100)
preds = generator.predict(try_input)
plt.figure(figsize=(10,10))
for i in range(preds.shape[0]):
plt.subplot(10, 10, i+1)
plt.imshow(preds[i, :, :, 0], cmap='gray')
plt.axis('off')
# tight_layout minimizes the overlap between 2 sub-plots
plt.tight_layout()
plot_output()

Generate new numbers from GAN learned over 60 epochs#
Load the learned weights and apply them for generating fake images:
generator.load_weights('gen_60_scaled_images.h5')
discriminator.load_weights('dis_60_scaled_images.h5')
plot_output()
