
Gaussian Process
Contents
Gaussian Process#
Introduction#
In the previous sections parametric and non-parametric supervised ML-methods have been introduced. In parametric algorithms, such as Linear Regression one assumes a certain model type (e.g. the model is a linear function) and the algorithm learns the parameters of this model type (e.g. slope and bias) such that the concrete model fits well to the given training data. One the other hand a non-parametric approach such as K-Nearest Neighbors does not require any assumptions about the model-type and it does not learn any parameters, that define a model. Instead it just saves all training data and predicts the output of new data by determining the nearest training instances.
Parametric methods are weak, if the assumption on the model-type is inadequate. After the training phase the entire knowledge of the training data is compressed in a few model parameters. This may constitute waste of information. For example, after training we do not know in which regions much training data has been available and hence predictions may have an increased reliabilty. The drawback of non-parametric methods is their large memory footprint and their long inference time. Moreover, since we do not have a model, predictions in regions, where no training-data has been available, are quite unreliable.
In this context a Gaussian Process can be considered to be a semi-parametric supervised ML-algorithm. In the inference phase the predictions are calculated from training data. It is not necessary to assume a certain model type (therefore non-parametric). However, one must assume a way how predictions are calculated from training data and possibly learn parameters, which specify this way (therefore parametric).
Gaussian Processes can be applied for regression and classification. However, in practice they are mostly applied for regression. In this lecture only the regression-case is considered.
Recap Gaussian Normal Distribution#
A Gaussian Process is closely related to a Multidimensional Gaussian Distribution. Therefore, we first recall univariate and multivariate Gaussian distributions, before the Gaussian Process and it’s application for Regression will be described.
Univariate#
The Probability Density Function (PDF) of a Gaussian distribed random variable \(X\) is:
where \(\mu\) is the mean and \(\sigma\) is the standard deviation. This distribution is plotted below for two different standard deviations.
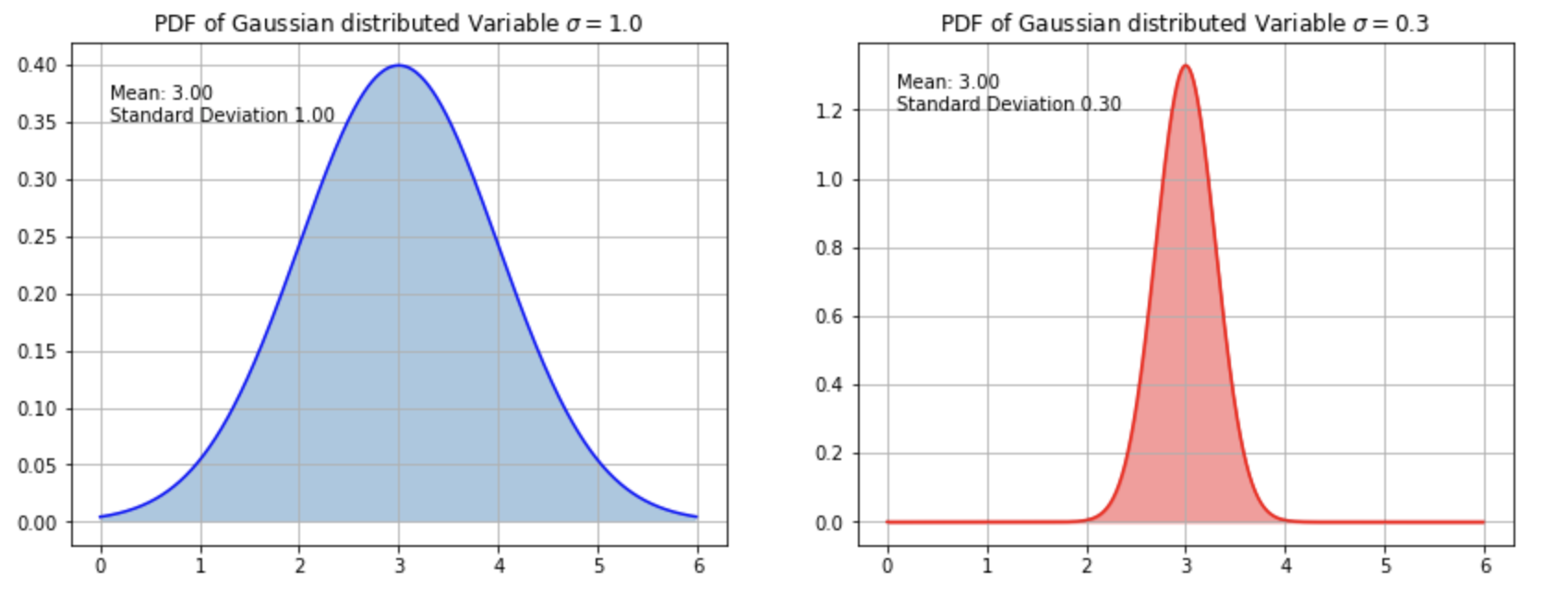
Fig. 18 PDFs of univariate Gaussian distribution with different standard deviations.#
In the sequel a Gaussian distributed random variable \(X\) with mean \(\mu\) and standard deviation \(\sigma\) is denoted by
Estimate parameters from data:
The univariate Gaussian distribution, as defined in equation (52) is completely defined by the parameters \(\mu\) and \(\sigma\). If a sample of \(Z\) values \(x_i\) of a univariate random variable \(X\) is given and it can be assumed that the random variable is Gaussian distributed, the mean-value and the standard deviation can be estimated as follows.
Estimate for \(\mu\):
Estimate for \(\sigma\):
Multivariate#
The Probability Density Function (PDF) of a Multidimensional Gaussian Distribution is:
Here
\(\mathbf{x}=\left[x_1,x_2,\ldots,x_d \right]\) are the values of \(d\) random variables, which are jointly Gaussian distributed.
the mean-value-vektor is
(54)#\[ \mathbf{\mu}=[\mu_1,\mu_2,\ldots, \mu_d] \]the covariance matrix is
(55)#\[\begin{split} \Sigma = \left( \begin{array}{cccc} \sigma_{11}^2 & \sigma_{12} &\cdots & \sigma_{1d} \\ \sigma_{21} & \sigma_{22}^2 &\cdots & \sigma_{2d} \\ \vdots & \vdots & \ddots & \vdots \\ \sigma_{d1} & \sigma_{d2} & \cdots & \sigma_{dd}^2 \\ \end{array} \right) \end{split}\]In this matrix the elements on the principal diagonal \(\sigma_{ii}^2\) are the variances along the corresponding axis. All other elements are covariances, which describe the correlation between the axes. If \(\sigma_{ij}=0\), then the random variables \(X_i\) and \(X_j\) are not correlated. The higher the absolute value of \(\sigma_{ij}\), the stronger the correlation. From the variances and the covariances the linear correlation-coefficient \(\rho_{ij}\) can be calculated as follows:
(56)#\[ \rho_{ij}=\frac{\sigma_{ij}}{\sigma_{ii} \sigma_{jj}} \]The correlation coefficient has a value-range from \(-1\) to \(1\) and helps to better quantify the correlation between the axis.
\(|\Sigma|\) is the determinant of the covariance matrix
\(\Sigma^{-1}\) is the inverse of the covariance matrix
Below, the PDF of a 2-dimensional Gaussian distribution with
and
is plotted.

Fig. 19 PDF of a 2-dimensional Gaussian distribution.#
Estimate parameters from data:
In order to estimate a multi-dimensional Gaussian distribution from a dataset \(T\), the mean-value-vektor \(\mathbf{\mu}\) and the covariance matrix \(\mathbf{\Sigma}\) must be estimated.
We denote the estimation of the mean-value-vektor \(\mu\) by \(m=[m_1,m_2,\ldots m_N]\). The components of this vektor are just the columnwise mean-values of the datamatrix:
where \(x_{k,i}\) is the value of random variable \(X_i\) of instance \(k\).
Moreover, the estimation of the covariance matrix \(\Sigma\) is denoted by \(S\). And the components of \(S\) are
the estimations of the variances \(\sigma_{ii}^2\), which are denoted by \(s_{ii}^2\)
the estimations of the covariances \(\sigma_{ij}\), which are denoted by \(s_{ij}\).
From a given dataset \(T\) with \(Z\) instances (rows) and \(N\) random variables (columns), the variances and covariances are estimated as follows:
Below for two distinct 2-dimensional Gaussian distributions the PDF and a corresponding data sample are visualized. In the first example the two random variables are uncorrelated, in the second plot correlated.
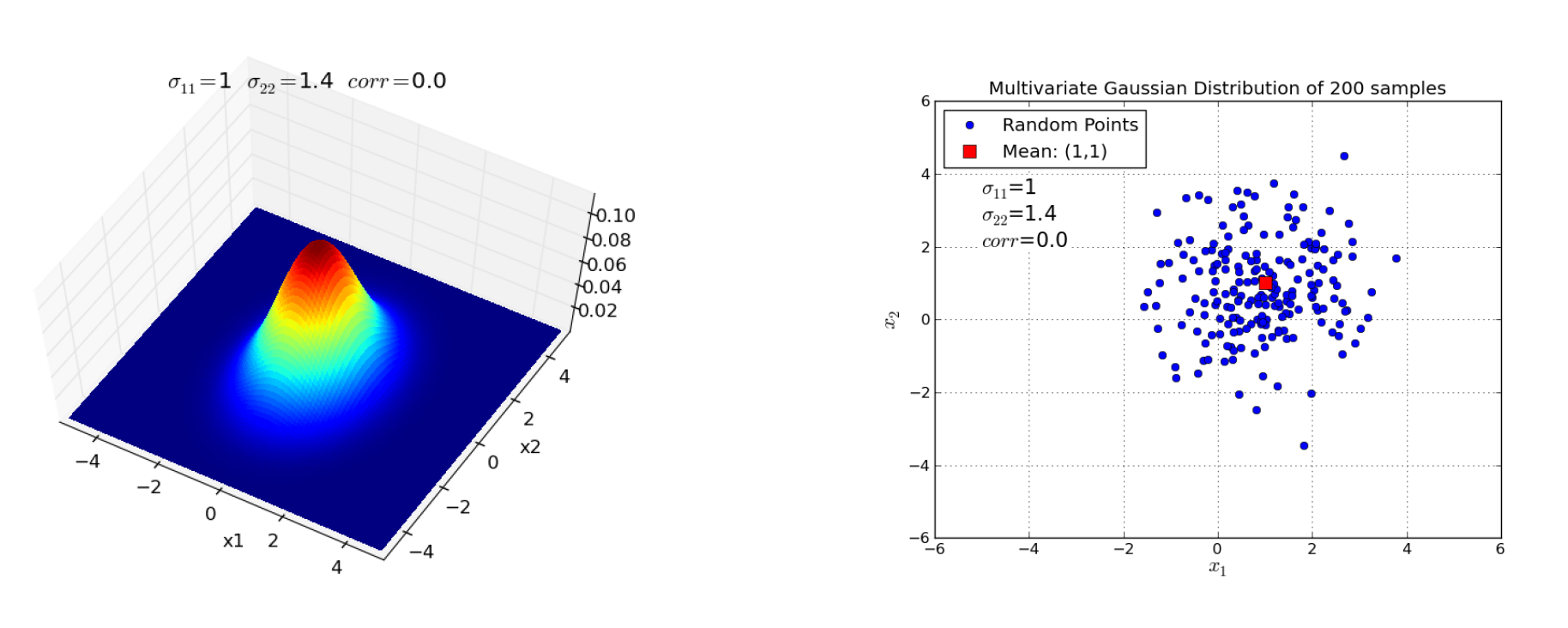
Fig. 20 Left: PDF of a 2-dimensional Gaussian distribution with no correlation between the two random variables \(X_1\) and \(X_2\). Right: Sample of data, drawn from the PDF on the left hand side.#
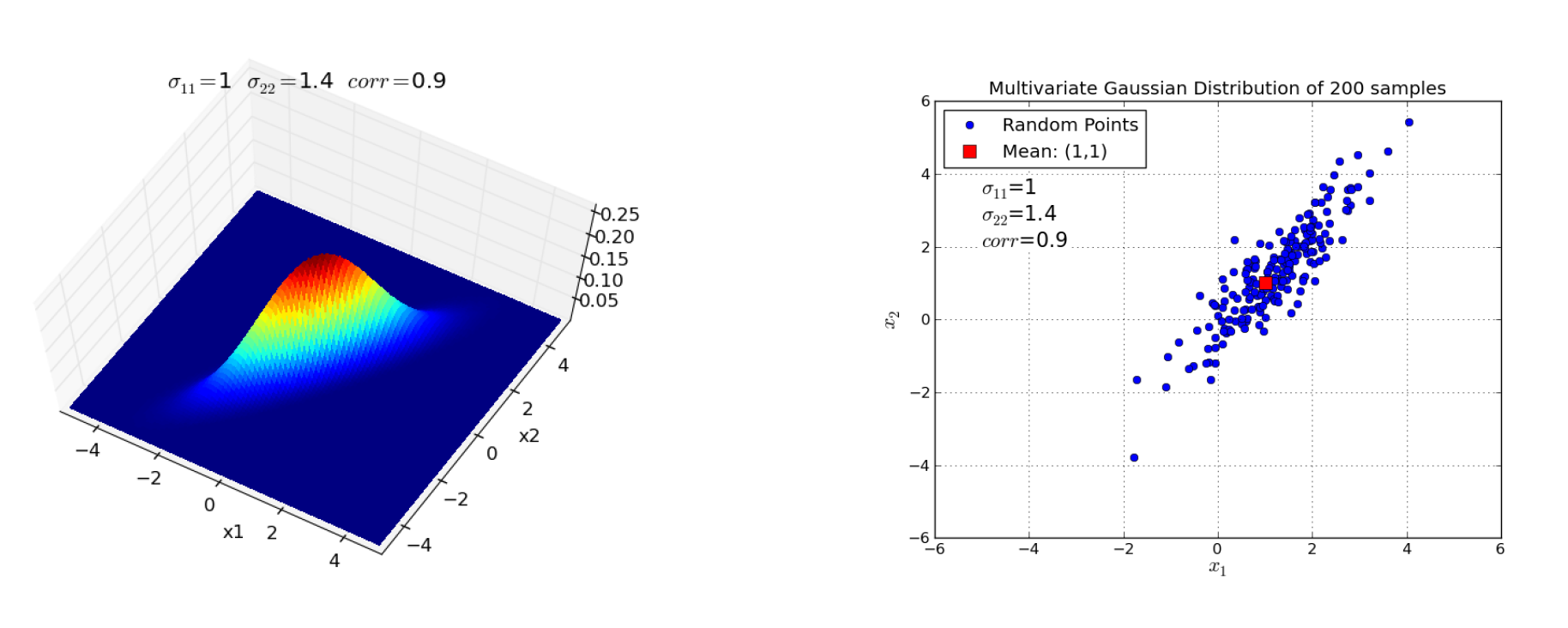
Fig. 21 Left: PDF of a 2-dimensional Gaussian distribution with strong positive correlation between the two random variables \(X_1\) and \(X_2\). Right: Sample of data, drawn from the PDF on the left hand side.#
Gaussian Process#
After recalling Multidimensional Gaussian Distributions, it’s no big deal to understand Gaussian Processes. In a nutshell: Multidimensioanl Gaussian Distributions are distributions over a finite set of \(d\) correlated random variables. A Gaussian Process extends this to an infinite set of random variables. This extension is sketched in the image below:
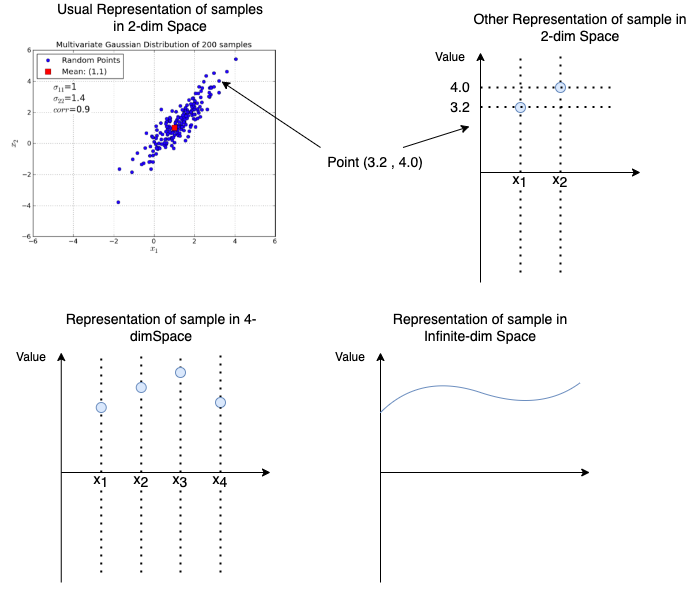
Fig. 22 The top-left plot contains the usual represenations of samples of a 2-dimensional Gaussian Distribution. The top-right displays another representation of a single sample with coordinates (3.2 , 4.0). In the lower-left it is sketched how this representation can be extended to an arbitrary number of dimensions. In the lower-right plot the number of dimensions is infinite. The result is a sample of a Gaussion Process.#
The differences between Multidimensional Gaussian Distributions and Gaussian Processes are listed in the two panels below:
Multidimensional Gaussian Distribution
Joint Distribution over d Gaussian Variables
\[ X=\left[ X_1,X_2,\ldots X_d \right] \]At each index \(i\), with \(i \in \{1,\ldots,d\}\) a Gaussian distributed variable \(X_i\) with mean \(\mu_i\) and variance \(\sigma_i\) is defined.
The random variables \(X_i\) and \(X_j\) are correlated with covariance \(\sigma_{ij}\)
Each subset of the \(d\) random variables is again a Multidimensional Gaussian Distribution
The Multidimensional Gaussian Distribution is completely defined by it’s mean-vector \(\mathbf{\mu}=[\mu_1,\mu_2,\ldots, \mu_d]\) and it’s covariance matrix \(\Sigma\)
Gaussian Process
Distribution over continous functions
\[ f(x) \]For each \(x\) with \(-\infty < x < \infty\) a Gaussian distributed \(f(x)\) with mean \(m(x)\) and variance \(k(x,x)\) is defined.
The function values \(f(x_i)\) and \(f(x_j)\) are correlated with covariance \(k(x_i,x_j)\)
Each finite subset of the infinity number of function values \(f(x_i)\) is a Multidimensional Gaussian Distribution
The Gaussian Process is completely defined by it’s mean-function \(m(x)\) and it’s covariance function \(k(x_i,x_j)\)
Gaussian Process
A Gaussian Process is a Probabilistic Distribution over functions \(f(x)\), with \(-\infty < x < \infty\). Since there exists an infinite number of values for \(x\) it can be considered as an infinite-dimensional Gaussian distribution. Each finite subset of function-values \(f(x_1),f(x_2),\ldots,f(x_d)\) is a usual Multidimensional Gaussian Distribution.
In the sequel a Gaussian Process with mean-function \(m(x)\) and covariance function \(k(x,x')\) is denoted by
Covariance Function#
The most common covariance-function \(k(x,x')\) is the squared exponential
Parameters and characteristics of this covariance function are
The correlation between \(f(x)\) and \(f(x')\) decreases with increasing distance between \(x\) and \(x'\).
Length-Scale \(\ell\): The higher \(\ell\) the slower the decrease of the correlation between \(f(x)\) and \(f(x')\) with increasing distance between \(x\) and \(x'\). A high value \(\ell\) means strong correlation between neighbouring function-values. This yields smooth curves. Small values for \(\ell\) means less correlation and the potential for high differences in neighbouring function-values.
Variance \(\sigma_f^2\). This is the maximal covariance value and defines the value on the main diagonal of the covariance-matrix. This hyperparameter should be large, if one can assume a strong deviation around the mean-value.


Generate Samples of Gaussian Process#
Even though functions assign one function value to each argument of a possibly infinite domain, in computer programs functions are evaluated always at a finite set of arguments. Therefore, in computer programs one can think of functions as tables, in which to each domain value \(x\) a corresponding function value \(f(x)\) is mapped. Since in computer programs we always have finite subsets and any finite subset of a Gaussian Process is a Multidimensional Gaussisan Distribution, we can generate samples of a Gaussian Process in exactly the same was as we generate samples of a Multidimensional Gaussian Distribution. For generating samples of a Multidimensional Gaussian Distribution we have to specify the mean vector ((54)) and the covariance matrix ((55)).
The mean-value vector is obtained by evaluating the mean function \(m(x)\) at all \(x_i\) of the domain.
The covariance matrix \(K\) is obtained by evaluating the covariance function \(k(x,x')\) at all possible pairs of arguments, i.e. the entry in row \(i\), column \(j\) of the covariance matrix is \(k(x_i,x_j)\).
Example: Calculation of mean-vector and covariance matrix
Assume that the domain has only 4 elements
For the mean function
and the covariance function
the corresponding mean-vector and covariance matrix are:
and
respectively.
Implementation: Generate Samples of GP#
Below it is shown how samples of a Gaussian Process can be generated.
Generate domain, mean-vector and covariance-matrix:
import numpy as np
x=np.linspace(0,7,35)
mx=0.5+x*np.sin(x)
K=np.zeros((len(x),len(x)))
for i in range(len(x)):
for j in range(i,len(x)):
k=2*np.exp(-0.5*(x[i]-x[j])**2) #covariance function
K[i][j]=k
K[j][i]=k
Generate 3 samples of a Multidimensional Gausian Distribution
pointset=np.random.multivariate_normal(mx,K,3) #Erzeugt 3 Samples einer multivariaten
print(pointset)
Visualize the generated samples and the mean-function:
from matplotlib import pyplot as plt
from scipy import r_
plt.figure(figsize=(10,10))
plt.plot(x,mx,label="mean $m(x)=0.5+x*sin(x)$")
plt.plot(x,pointset[0],'--',color="gray")
plt.plot(x,pointset[1],'-.',color="gray")
plt.plot(x,pointset[2],color="gray")
plt.text(0.5,6,"$m(x)=0.5+x*sin(x)$ \n$k(x,x')=2 \cdot \exp(0.5\cdot(x-x')^2)$",fontsize=14)
plt.title('Random Samples and Mean from a Gaussian Process')
plt.xlabel('x')
plt.ylabel('f(x)')
fillx = r_[x, x[::-1]]
vars=np.diag(K)
stds=np.sqrt(vars)
filly = r_[mx+2*stds, mx[::-1]-2*stds[::-1]]
plt.fill(fillx, filly, facecolor='gray', edgecolor='white', alpha=0.3)
plt.show()

Fig. 25 3 Samples of a Gaussian Process#
Gaussian Process Regression#
In the previous subsection it was described how samples of a Gaussian Process can be generated, given a mean-function and a covariance function. However, up to now nothing has been said, how this can be applied for a supervised ML regression task. The idea is that the Gaussian Process with defined mean- and covariance function constiute a prior. On the basis of this prior we calculate a posterior for the given training data
In particular the given training data are considered to be support-points of a sample from
and we can calculate all other points \((x,f(x))\) on this particular GP sample from the mean- and covariance function and the given support-points. The prediction at an arbitrary argument \(x\) is \(f(x)\).
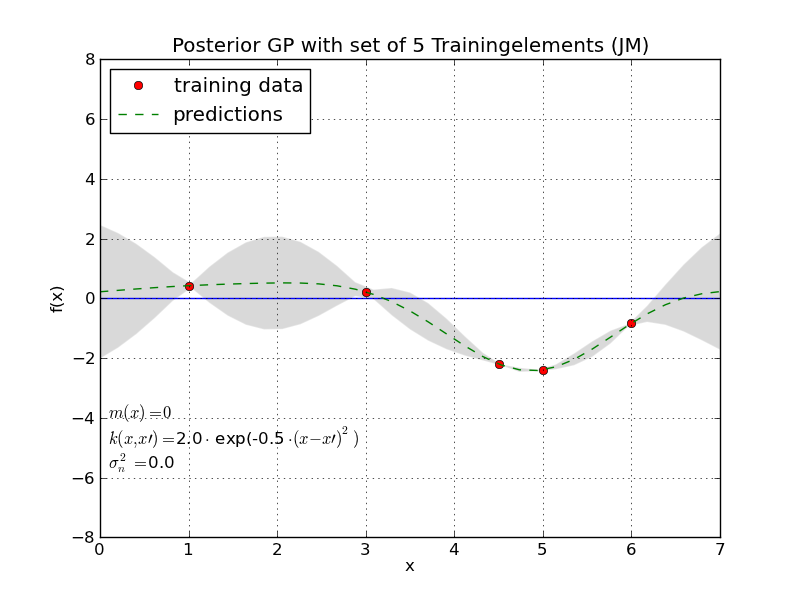
Fig. 26 Training data is considered to constitute support-points (red) of a GP sample. By applying the mean- and covariance-function of the GP all other points of this sample (green dashed line) can be determined.#
Recall that in Linear Regression, it is assumed that the output \(y_t\) is the sum of a deterministic term \(f(x_t)\) and a noise term \(n_t\)
The noise term \(n_t\) is assumed to be a sample of a 1-dimensional Gaussian distribution with zero mean and variance \(\sigma_n^2\). In Linear Regression one tries to estimate a good approximation
for the determinisic part \(f(x)\). This approximation \(g(x)\) minimizes the Mean Squared Error between the given labels \(y\) and the model’s prediction \(g(x)\) on the training data.
Now in Gaussian Process Regression we assume that training data constitutes support-points on a sample of a Gaussian Process with predefined mean- and covariance function. In contrast to Linear Regression now the assumption is
where \(z_t\) is considered to be a component of a sample of an N-dimensional Gaussian Distribution with zero mean. As in Linear Regression \(n_t\) is assumed to be a sample of a 1-dimensional Gaussian distribution with zero mean and variance \(\sigma_n^2\). It is independent of all other training instances. The independent noise term \(n_t\) and the correlated noise term \(z_t\) can be integrated into a single Multidimensional Gaussian distribution by adding the term
to the covariance function \(k(x,x')\), with the Kronecker function
For example if the original covariance function is the squared exponential, as definied in equation (57) the new covariance function which integrates the noise term is
If the covariance-matrix is calculated with this noise-integrating covariance function the difference to the covariance matrix without noise-integration is, that now the values of the main diagonal are \(\sigma_f^2+\sigma_n^2\), rather than \(\sigma_f^2\).
The main differences between GP Regression and Linear Regression are:
in GP Regression the covariances between the training-instances are regarded, i.e. dependecies between neighboring training instances are taken into account.
in GP Regression the goal is not to learn an approximation for \(f(x)\). Instead, the values \(y_*\) at the arguments of interest \(x_*\) are estimated directly.
The first difference has already been discussed in the context of the assumption stated in equation (60). In the sequel we will take a look on the second difference. In particular it will be described how the predictions \(y_*\) will be calculated for new inputs \(x_*\):
As we already know, the mean vector \(\boldsymbol\mu\) and the covariance matrix \(K\) can be calculated from the training dataset \(T=\{x_t,y_t \}_{t=1}^N\). The targets of the training dataset \(\mathbf{y} = [y_1, y_2, \ldots y_N]\) constitute a sample of an \(N-\)dimensional Gaussian Distribution
Now, if we want to estimate the value of \(y_*\) at a new input of interest \(x_*\), we assume that the extended target vector
is a sample of an \((N+1)-\)dimensional Gaussian Distribution with mean vector
and covariance matrix
where
The corresponding notation is
Since the values of \(\mathbf{y} = [y_1, y_2, \ldots y_N]\) are given, we are not interested in the joint distribution, but rather in the conditional distribution for \(y_*\), given \(\mathbf{y}=[y_1, y_2, \ldots y_N]\):
It is known, that the conditional probability distribution of a multidimensional Gaussian distribution (see figure Fig. 27) is also a multidimensional Gaussian distribution, which in the given case is specified as follows:
GP Regression: predict target \(y_*\) at input \(x_*\)
The prediction \(y_*\) is the mean
The corresponding variance of the prediction is
and the standard-deviation of the prediction \(y_*\) is
Here \(diag(X)\) is the main-diagonal of matrix \(X\). In equation (66) the argument of \(diag()\) is a single value, if the prediction \(y_*\) has been calculated only at a single input \(x_*\), but it is a \(Z \times Z\) matrix, if predictions are calculated at \(Z\) inputs.
The standard deviations \(std(y_*)\) indicate, that the confidence that the true prediction lies within an interval \(y_* \pm 2 \cdot std(y_*)\) is \(95\%\).
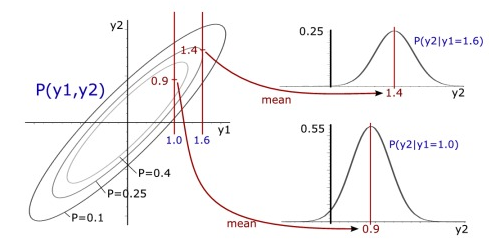
Fig. 27 The conditional probability distribution of a 2-dimensional Gaussian distribution is a 1-dimensional Gaussian distribution#
GP Regression: predict target \(\mathbf{y_*}=[y_{*1},y_{*2},\ldots, y_{*Z} ]\) at many inputs \(\mathbf{x_*}=[x_{*1},x_{*2},\ldots, x_{*Z} ]\)
Calculation of \(\boldsymbol\mu_*\) (to be used in (62)):
Calculation of \(K_*\) (to be used in (63))
Calculation of \(K_{**}\) (to be used in (63))
Apply \(\boldsymbol\mu_*\), \(K_*\) and \(K_{**}\) in equations (65) and (66) in order to compute all \(Z\) predictions in one step.
Example: GP Regression
Task: For the training dataset
predictions at the inputs \(x=5, x=6\) and \(x=7\) and the corresponding reliability of the predictions shall be calculated. The mean function is
and the covariance function which integrates the noise \(\sigma_n^2=0.005\) is
Solution:
In order to calculate equations (65) and (66), first the required matrices must be determined:
Covariance Matrix of training data (equation (59)):
\[\begin{split} K=\left( \begin{array}{cccc} 2.005 & 1.213 & 0.271 & 0.022 \\ 1.213 & 2.005 & 1.213 & 0.271 \\ 0.271 & 1.213 &2.005 & 1.213 \\ 0.022 & 0.271 & 1.213 & 2.005 \\ \end{array} \right) \end{split}\]Inverse of \(K\):
\[\begin{split} K^{-1}=\left( \begin{array}{cccc} 0.953 & -0.862 & 0.519 & -0.208 \\ -0.862 & 1.688 &-1.219 & 0.519 \\ 0.519 & -1.219 & 1.688 & -0.862 \\ -0.208 & 0.519 & -0.862 & 0.953 \\ \end{array} \right) \end{split}\]Covariance between training data inputs \(x\) and inputs \(x_*\), for which predictions \(y_*\) shall be calculated (equation (68)):
\[\begin{split} K_{*}=\left( \begin{array}{cccc} 6.7\cdot 10^{-4} & 2.22\cdot 10^{-2} & 2.706\cdot 10^{-1} & 1.2130 \\ 7.4\cdot 10^{-6} & 6.7\cdot 10^{-4} & 2.22\cdot 10^{-2} & 2.706\cdot 10^{-1} \\ 3.1\cdot 10^{-8} & 7.4\cdot 10^{-6} & 6.70\cdot 10^{-4} & 2.22\cdot 10^{-2} \\ \end{array} \right) \end{split}\]Covariance between different inputs \(x_*\), for which predictions \(y_*\) shall be calculated (equation (69)):
Applying equation (65) the estimation \(\mathbf{y_*}=[y_{5},y_{6},y_{7} ]\) at the inputs \(\mathbf{x_*}=[5,6,7]\) can be calculated to be:
The standard deviation of the predictions is, according to equations (66) and (67)
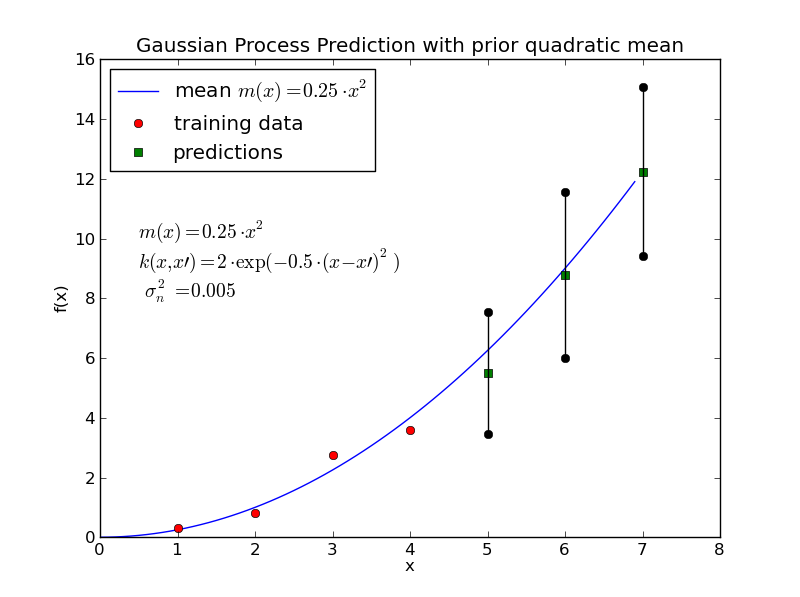
Fig. 28 Training data (red points), predictions \(y_*\) (green points) and the \(95\%\)-confidence intervalls around the predictions (vertical bars) for this example#
Learn hyperparameters of mean- and covariance-function#
Up to now we have assumed, that the mean \(m(x)\) and the covariance \(k(x,x')\) are predefined. The question where the necessary knowledge for the definition of these functions comes from has been ignored so far. In general there exists two options:
Domain Knowledge: Somebody knows the rough structure of the data (i.e. increasing or periodic) and mean and covariance are configured according to this rough structure. Note that in this way Gaussian Processes provide a comfortable way to integrate domain knowledge into supervised learning.
Data Knowledge: If enough training data is available the hyperparameters of the mean- and covariance-function can be learned.
In this section we consider the second option, i.e. we describe How to learn the hyperparameters of \(m(x)\) and \(k(x,x')\). It is important to note, that the types of the functions must also be pre-selected, only the hyperparameters of the corresponding function types are learned. For example one can assume
a quadratic mean function of type
and a squared exponential covariance function of type
Then the set of hyperparameters, which can be learned from data is
In order to determine these hyperparameters a Maximum Likelihood approach is applied. This means that the hyperparameters are specified such that the probability for the given training data \(\mathbf{x},\mathbf{y}\)
is maximized. Since, the logarithmic function is monotonic increasing one can equivalently maximize
This yields a simplification of the following calculations.
In the case of multivariate Gaussian distributed data this logartihmic probability is
where \(\boldsymbol\mu\) is the mean vector according to equation (58), \(K\) is the covariance matrix according to equation (59) and \(N\) is the number of training-instances. The hyperparameters are part of \(\boldsymbol\mu\) and \(K\). In order to find the hyperparameters, which maximize equation (70) one must apply a numeric optimisation algorithm. (see e.g. numeric optimisation with scipy). The application of such a numeric optimisation process is demonstrated in the next section. The numeric optimisation process, e.g. COBYLA, requires
the function, which must be minimized1 in parametric form
a list of start-values for all parameters
a list of constraints for all parameters
In the figure below learned GP regression modells for two different types of mean-function (same training data in both cases) are shown. Note that in the areas, where no training-data is available (\(x<1\) or \(x>9\)) the predictions approximate the learned mean-function and the uncertainty (variance) increases in these areas.
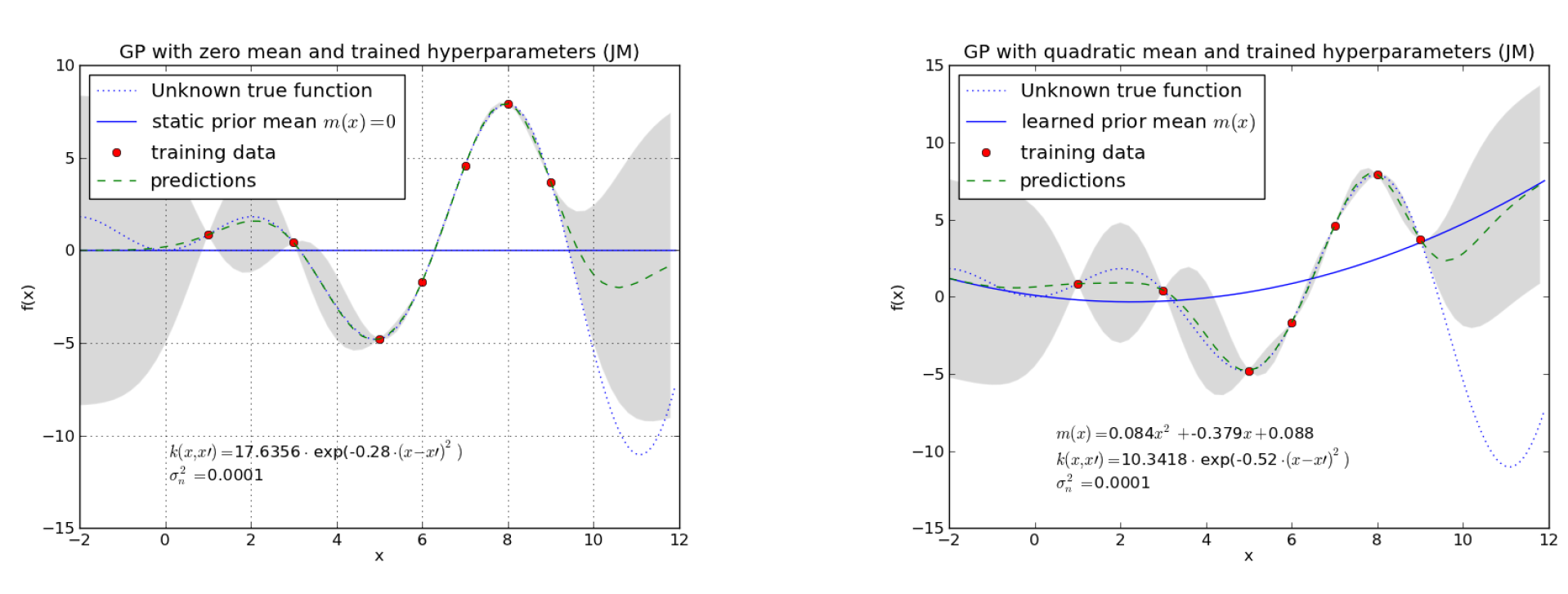
Fig. 29 Left: A static mean \(m(x)=0\) is assumed. Right: A quadratic mean of type \(m(x)=a x^2 + b x +c\) is assumed. In both cases a covariance function of type squared exponential has been assumed. The plot show the learned hyperparameters and the resulting GP regression models for both cases.#
Final remarks on the covariance function#
In the examples above covariance functions of type squared exponential have been applied. A crucial hyperparameter for this type of function is the horizontal length-scale \(\ell\). The figure below demonstrates the influence of this parameter.

Fig. 30 Decreasing horizontal length-scale \(\ell\) from top left to bottom right#
As can be seen a decreasing length-scale \(\ell\) yields
an increasing variance (uncertainty) in the ranges of no data
a faster approximation of the predictions to the mean-function
Even though the squared exponential is the most common covariance function, it does not fit in all cases. The sqaured exponential implies that correlation between neighbouring instances decreases with increasing distance between these instances. But this is not true for all types of data, as the figure below demonstrates. In both plots data has a long-term and a short-term-behaviour. In such cases more complex types of covariance functions are required.

A covariance functions, which may be suitable for the data in the left plot of the figure above is
If \(\ell_2\) has a significatnt higher value than \(\ell_1\), then the second term models long-term-correlations and the first term models short-term correlations between data.
A covariance functions, which may be suitable for the data in the right plot of the figure above is
Here the long-term behaviour is modelled by the first term and the periodic short-term behaviour is modelled by the second term.
In general arbitrary covariance-functions can be configured, as long as the corresponding covariance matrix \(K\) is positive definite.
For a deeper dive into Gaussian processes the tutorial [Ebd15] and the book [RW] are recommended.