
Intro and Overview Object Recognition Lecture¶
What is Object Recognition?¶
Goal of Computer Vision
Computer Vision seeks to enable machines to see and understand data from images and videos
Definition of Computer Vision
A branch of artificial intelligence and image processing concerned with computer processing of images from the real world. Computer vision typically requires a combination of low level image processing to enhance the image quality (e.g. remove noise, increase contrast) and higher level pattern recognition and image understanding to recognise features present in the image.
Object Recognition is the central task within Computer Vision. Other Computer-Vision tasks are e.g. image restoration, 3D-reconstruction, image rendering etc. Computer Vision itself is related with other sciences, as depicted in the image below:

Object recognition can be considered to be a subset of Machine Learning. The general process of Machine Learning (ML) consists of a training- and an inference-phase:
During the training-phase a ML-algorithm learns from a large set of labeled input (pairs of \((input/output)\)) a general model, which can be considered to be a function \(output=f(input)\).

Supervised learning training-phase: Learn an abstract model from many pairs of labeled input Inference Phase: The model \(output=f(input)\), which has been learned in the training-phase, is applied to calcultate for each new \(input\) the corresponding \(output\).

On a more technical level the concept of supervised Machine-Learning can be sketched as follows:

As shown in the figure above, the input usually must be transformed into a numeric representation (vector or multi-dimensional array), which must somehow contain the relevant information of the input.
In the case of Object Recognition, the \(input\) to the ML-process is either an image or a video and the \(output\) are the detected objects.
In object recognition the preprocessing block, is particularly important. There exist many different approaches to exract relevant features from images and videos and to encode these features into numeric representations. The performance and quality of an object recognition process strongly depends on the quality of the images, the type of feature extraction and the performance and suitability of the *applied Machine Learning algorithm.
Hence, this lecture can be partitioned into the subfields:
Basic Image Processing
Feature Extraction and Representation
Machine Learning Algorithms
Part 1: Basic Image Processing¶
The first block on basic image processing starts here. Image processing is performed by applying filters to images. The most important type of filtering - convolutional filtering - will be introduced in detail. In object recognition filters are applied e.g. for
enhancing the quality of images, e.g. by noise-suppression or contrast-enhancement
generating different versions, e.g. different scales or blurs, of an image
detecting features such as edges
keypoint-detection
template-matching
Part 2: Feature Extraction¶
The block on feature extraction starts here. For object recognition and other computer-vision tasks images must be described by one or more numeric representations. These numeric representations should contain the relevant features of the image. On an abstract level, the methods to calculate features from a given image can be categorized as follows:
Global features: One numeric representation (vector) is calculated for the entire image. Further recognition/identification applies this single image descriptor as input.

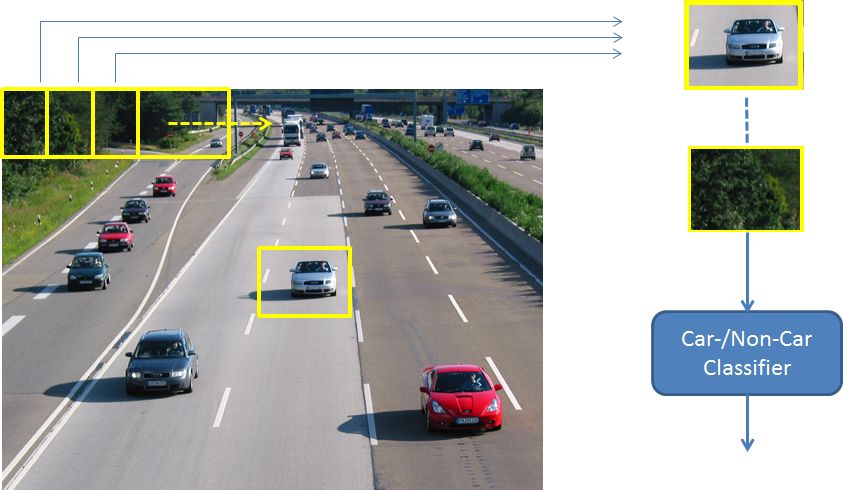
Subwindow features: The entire image is partitioned into subwindows. For each subwindow one numeric representation is calculated and recognition/identification is performed for each single subwindow.
Subspace features: The feature descriptor of the entire image or a subwindow can be transformed into a lower-dimensional space, e.g. by Principal Component Analysis (PCA), Singular Value Decomposition (SVD) or an Autoencoder. Recognition may perform better in the lower-dimensional space, than in the original space. Face recognition is often implemented on the basis of subspace features.

Local features: A set of numeric representations (vectors) is calculated for a given image. Each of these vectors describes a local area within the image. Further recognition/identification is performed by taking into account the entire set of local descriptors.

Part 3: Machine Learning Algorithm for Object Recognition¶
The general notion Object Recognition, can actually be subdivided into different dimensions and subtasks. Here we distinguish
General Object recognition: Determine which object-category, e.g. car, person, building etc. is in the image
Identification: Determine which concrete instance is in the image, e.g. which concrete person
A further distinction is shown in the image below:

Image Source: Blog Post: The Modern History of Object Recognition — Infographic and the corresponding Github repo
Today, most object recognition tasks can be solved best by Deep Nerual Networks. However, Deep Learning requires usually a large amount of labeled training data and the availability of sufficient computing power. Moreover, some tasks can still be solved better by applying conventional ML-approaches. In this lecture deep-learning as well as conventional ML-approaches are described.
Why Object Recognition is challenging?¶
The fact that about half of the cerebral cortex in primates is devoted to processing visual information gives some indication of the computational load one can expect to invest for this complex task.
Source: [FvE91]
Particularly in the case of
Image Retrieval with large image databases,
Image Recognition, where an image must be categorized in one of thousands of categories
highly efficient algorithms are required.
In the case of supervised learning labeled training data is required. In general labeling is cost-intensive.
Object recognition must be robust with respect to scale, illumination, translation and rotation, viewpoint, clutter, occlusion, pose, intra-class invariance:

Some Applications¶
Google Vision API¶

Image Retrieval¶

Image based Disease Detection¶

Forgery Detection¶

Optical Inspection¶

Autonomous Driving¶

Tracking¶

Pose Estimation¶

Style Transfer¶
Super Resolution¶

Image Generation¶

Generating Images from Text¶
