
1.1. Access and Analyse Contents of Textfiles¶
Author: Johannes Maucher
Last update: 2020-09-09
In this notebook some important Python string methods are applied. This Python string method docu provides a compact overview.
1.1.1. Character Encoding¶
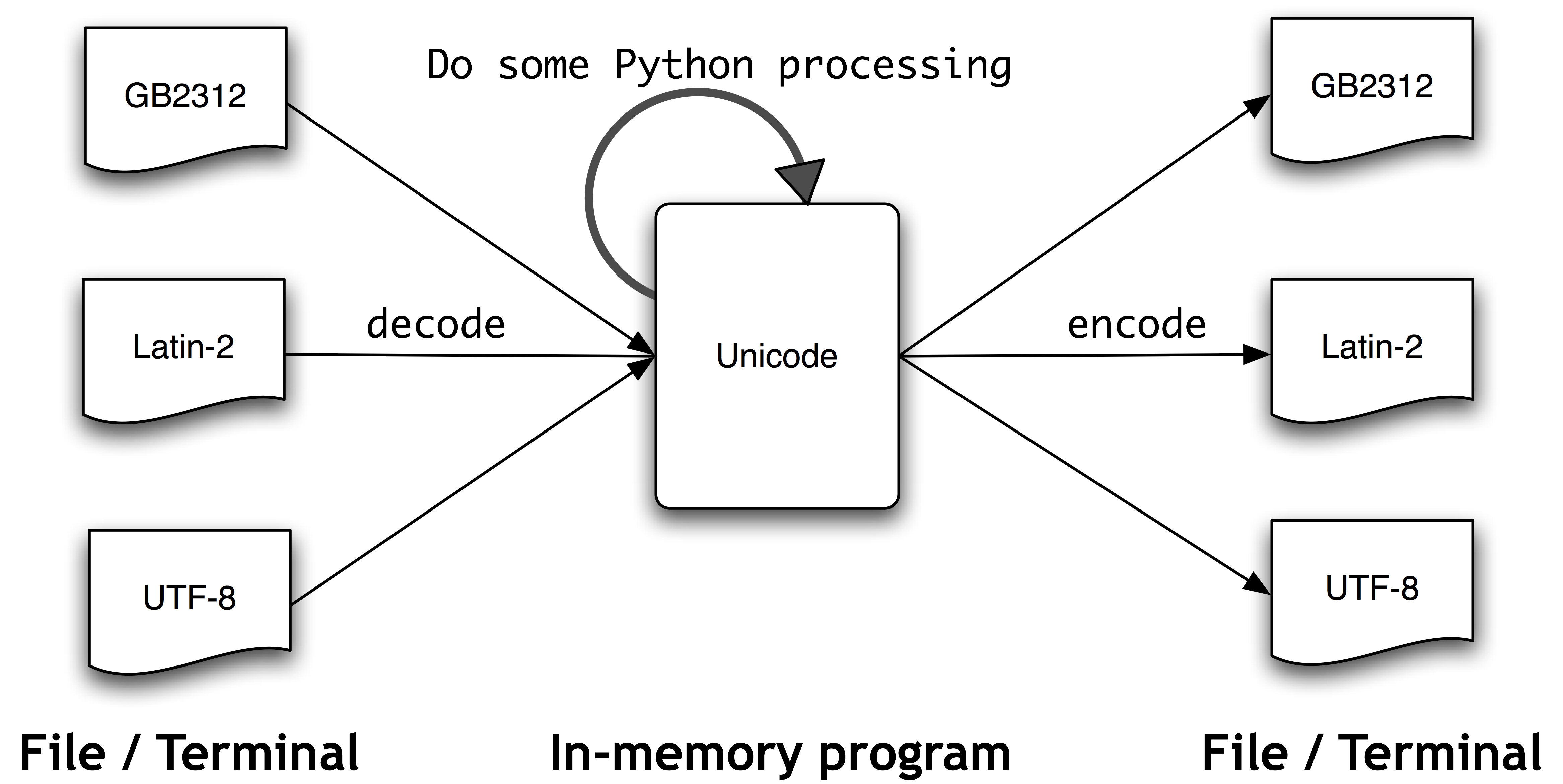
In contrast to Python 2.x in Python 3.y strings are stored as unicode, i.e. each string is a sequence of unicode code points. Unicode supports more than 1 million characters. Each character is represented by a code point.
For the efficient storage of strings they are encoded.
A
strcan be encoded intobytesusing theencode()method.bytescan be decoded tostrusing thedecode()method.
Both methods accept a parameter, which is the encoding used to encode or decode. The default for both is UTF-8.
The following code cells demonstrate the difference between strings and bytes:
s1="die tür ist offen"
print(s1) #print string
print(type(s1))
b1=s1.encode('utf-8')
print("After utf-8 encoding: ",b1)
print(type(b1))
b2=s1.encode('latin-1')
print("After latin-1 encoding: ",b2)
print(type(b2))
die tür ist offen
<class 'str'>
After utf-8 encoding: b'die t\xc3\xbcr ist offen'
<class 'bytes'>
After latin-1 encoding: b'die t\xfcr ist offen'
<class 'bytes'>
print("Wrong decoding: ",b1.decode("latin-1"))
print(b2.decode("latin-1"))
print(b1.decode("utf-8"))
#print(b2.decode("utf-8"))
Wrong decoding: die tür ist offen
die tür ist offen
die tür ist offen
1.1.2. Textfile from local machine¶
1.1.2.1. Read in row by row¶
The following code snippet demonstrates how to import text from a file, which is specified by its path and filename. The example text file is ZeitOnlineLandkartenA.txt. In this first snippet the text in the file is read line by line. Each line is stored into a single string variable. The string variables of all lines are stored in a Python list.
filename="../Data/ZeitOnlineLandkartenA.txt"
listOfLines=[]
with open(filename,"r",encoding="latin-1") as fin:
for line in fin:
line = line.strip()
print(line)
listOfLines.append(line)
print("Number of Lines: ",len(listOfLines))
Landkarten mit Mehrwert
Ob als Reiseführer, Nachrichtenkanal oder Bürgerinitiative: Digitale Landkarten lassen sich vielseitig nutzen.
ZEIT ONLINE stellt einige der interessantesten Dienste vor.
Die Zeit, in der Landkarten im Netz bloß der Routenplanung dienten, ist längst vorbei. Denn mit den digitalen Karten von Google Maps und der Open-Source-Alternative OpenStreetMap kann man sich spannendere Dinge als den Weg von A nach B anzeigen lassen. Über offene Programmschnittstellen (API) lassen sich Daten von anderen Websites mit dem Kartenmaterial verknüpfen oder eigene Informationen eintragen. Das Ergebnis nennt sich Mashup ein Mischmasch aus Karten und Daten sozusagen. Die Bewertungscommunity Qype nutzt diese Möglichkeit schon lange, um Adressen und Bewertungen miteinander zu verknüpfen und mithilfe von Google Maps darzustellen. Auch Immobilienbörsen, Branchenbücher und Fotodienste kommen kaum noch ohne eigene Kartenfunktion aus. Dank der Integration von Geodaten in Smartphones werden soziale
Kartendienste immer beliebter. Auch sie nutzen die offenen Schnittstellen. Neben kommerziellen Diensten profitieren aber auch Privatpersonen und unabhängige
Projekte von den Möglichkeiten des frei zugänglichen Kartenmaterials. Das Open-Data-Netzwerk versucht, öffentlich zugängliche Daten zu sammeln und neue
Möglichkeiten für Bürger herauszuarbeiten. So können Anwohner in England schon länger über FixMyStreet Reparaturaufträge direkt an die Behörden übermitteln.
Unter dem Titel Frankfurt-Gestalten gibt es seit Frühjahr ein ähnliches Pilotprojekt für Frankfurt am Main. Hier geht es um weit mehr als Reparaturen. Die Seite soll
einen aktiven Dialog zwischen Bürgern und ihrer Stadt ermöglichen partizipative Lokalpolitik ist das Stichwort. Tausende dieser Mashups und Initiativen gibt es inzwischen. Sie bewegen sich zwischen bizarr und faszinierend, unterhaltsam und informierend. ZEIT ONLINE stellt einige der interessantesten vor. Sie zeigen, was man mit öffentlichen Datensammlungen alles machen kann.
Number of Lines: 10
1.1.2.2. Read in text as a whole¶
The entire contents of the file can also be read as a whole and stored in a single string variable:
with open(filename,"r",encoding="latin-1") as fin:
text=fin.read()
print(text[:300])
print("\nNumber of Characters in Text: ",len(text))
Landkarten mit Mehrwert
Ob als Reiseführer, Nachrichtenkanal oder Bürgerinitiative: Digitale Landkarten lassen sich vielseitig nutzen.
ZEIT ONLINE stellt einige der interessantesten Dienste vor.
Die Zeit, in der Landkarten im Netz bloß der Routenplanung dienten, ist längst vorbei. Denn mit den di
Number of Characters in Text: 2027
1.1.3. Segmentation of text-string into words¶
The entire text, which is now stored in the single variable text can be split into it’s words by applying the split()-method. The words are stored in a list of strings (wordlist). The words in the wordlist may end with punctuation marks. These marks are removed by applying the python string-method strip().
wordlist=text.split()
print("First 12 words of the list:\n",wordlist[:12])
cleanwordlist=[w.strip('().,:;!?-"').lower() for w in wordlist]
print("First 12 cleaned words of the list:\n",cleanwordlist[:12])
print("Number of tokens: ",len(cleanwordlist))
print("Number of different tokens (=size of vocabulary): ",len(set(cleanwordlist)))
First 12 words of the list:
['Landkarten', 'mit', 'Mehrwert', 'Ob', 'als', 'Reiseführer,', 'Nachrichtenkanal', 'oder', 'Bürgerinitiative:', 'Digitale', 'Landkarten', 'lassen']
First 12 cleaned words of the list:
['landkarten', 'mit', 'mehrwert', 'ob', 'als', 'reiseführer', 'nachrichtenkanal', 'oder', 'bürgerinitiative', 'digitale', 'landkarten', 'lassen']
Number of tokens: 267
Number of different tokens (=size of vocabulary): 187
1.1.4. Textfile from Web¶
from urllib.request import urlopen
import nltk
import re
Download Alice in Wonderland (Lewis Carol) from http://textfiles.com/etext:
print("-"*100)
print("-"*30+"1. Download Alice in Wonderland"+"-"*20)
urlAlice="http://textfiles.com/etext/FICTION/alice.txt"
#urlAlice="https://archive.org/stream/alicewonderlanda00carr/alicewonderlanda00carr_djvu.txt"
rawAlice=urlopen(urlAlice).read().decode("latin-1")
----------------------------------------------------------------------------------------------------
------------------------------1. Download Alice in Wonderland--------------------
print("First 4000 characters of downloaded text:\n",rawAlice[:4000])
First 4000 characters of downloaded text:
PROJECT GUTENBERG AND DUNCAN RESEARCH SHAREWARE
(c)1991
Project Gutenberg has made arrangements with Duncan Research for
the distribution of Duncan Research Electronic Library text. No
money is solicited by Project Gutenberg. All donations go to:
Barbara Duncan
Duncan Research
P.O. Box 2782
Champaign, IL
61825 - 2782
Please, if you send in a request for information, donate enough,
or more than enough to cover the cost of writing, printing, etc.
as well as the cost of postage.
This is Shareware, you may post it intact anywhere, as long as a
profit is not incurred.
As Shareware, no legal obligation is assumed by you to donate in
manners monetary or assistance in the creations or distributions
of electronic texts. These files are claimed under copyright to
protect their integrity, therefore you are required to pass them
on intact, but you may make changes to your own copies. We want
to know if any mistakes you find, so we can correct them in text
editions to come. We hope you will want to donate texts of your
own for distribution in this manner. If you would like payments
in the same manner as above, just include a similar statement.
Neither Prof. Hart nor Project Gutenberg nor Duncan Research has
any official connection with the University of Illinois.
*****************************************************************
Project Gutenberg Release 2.7a of Alice in Wonderland
These electronic texts of the classics are released in the CopyLeft
traditions of the Free Software Foundation and Richard M. Stallman.
This means the document is to be considered under copyright, and an
individual may make as may copies for self and/or friends, etc. and
will be under no obligation as long as this is not commercial. Not
for profit corporations and all other corporate entities are not to
distribute this file for any more cost to the user than $2 and only
if a disk is provided for that fee, including all shipping-handling
and/or other fees associated with that disk. If this file is to be
included with any other hardware, software or other material no fee
may be charged for this file. If anyone finds an error, and we are
sure you will, please email location of the errors to hart@uiucvmd,
(BITNET) or hart@vmd.cso.uiuc.edu (INTERNET), or to Duncan Research
via U.S. Mail at the address below.
Please mail corrections to the above address, or via email to:
hart@uiucvmd.bitnet
or
hart@vmd.uiuc.cso.edu
Neither Prof. Hart nor Project Gutenberg nor Duncan Research has
any official connection with the University of Illinois.
ALICE'S ADVENTURES IN WONDERLAND
Lewis Carroll
THE MILLENNIUM FULCRUM EDITION 2.7a
(C)1991 Duncan Research
CHAPTER I
Down the Rabbit-Hole
Alice was beginning to get very tired of sitting by her sister
on the bank, and of having nothing to do: once or twice she had
peeped into the book her sister was reading, but it had no
pictures or conversations in it, `and what is the use of a book,'
thought Alice `without pictures or conversation?'
So she was considering in her own mind (as well as she could,
for the hot day made her feel very sleepy and stupid), whether
the pleasure of making a daisy-chain would be worth the trouble
of getting up and picking the daisies, when suddenly a White
Rabbit with pink eyes ran close by her.
There was nothing so VERY remarkable in that; nor did Alice
think it so VERY much out of the way to hear the Rabbit say to
itself, `Oh dear! Oh dear! I shall be late!' (when she thought
it over afterwards, it occurred to her that she ought to have
wondered at this, but at the time it all seemed quite natural);
but when the Rabbit actually TOOK A WATCH OUT OF ITS WAISTCOAT-
POCKET, and looked at it, and then hurried on, Alice started to
her feet, for it flashed across her mind that she had never
before se
Save textfile in local directory:
with open("../Data/AliceEnglish.txt","w") as fout:
fout.write(rawAlice)
Read textfile from local directory:
with open("../Data/AliceEnglish.txt","r") as fin:
rawAlice=fin.read()
print("Type of variable: ", type(rawAlice))
print("Number of characters in the book: ",len(rawAlice))
Type of variable: <class 'str'>
Number of characters in the book: 150886
1.1.5. Simple Methods to get a first impresson on text content¶
In a first analysis, we want to determine the most frequent words. This shall provide us a first impression on the text content.
1.1.5.1. Questions:¶
Before some simple text statistics methods (word-frequency) are implemented inspect the downloaded text. What should be done in advance?
1.1.5.2. Remove Meta-Text¶
The downloaded file does not only contain the story of Alice in Wonderland, but also some meta-information at the start and the end of the file. This meta-information can be excluded, by determining the true start and end of the story. The true start is at the phrase CHAPTER I and the true end is before the phrase THE END.
startText=rawAlice.find("CHAPTER I")
endText=rawAlice.find("THE END")
print(startText)
print(endText)
rawAlice=rawAlice[startText:endText]
2831
150878
1.1.5.3. Tokenisation¶
Split the relevant text into a list of words:
import re
aliceWords = [word.lower() for word in re.split(r"[\s.,;´`:'()!?\"-]+", rawAlice)]
#aliceWords = [word.lower() for word in re.split(r"[\W`´]+", rawAlice)]
#aliceWords =["".join(x for x in word if x not in '?!().´`:\'",<>-»«') for word in rawAlice.lower().split()]
#aliceWords =["".join(x for x in word if x not in '?!.´`:\'",<>-»«') for word in rawAlice.lower().split()]
1.1.5.4. Generate Vocabulary and determine number of words¶
numWordsAll=len(aliceWords)
print("Number of words in the book: ",numWordsAll)
aliceVocab = set(aliceWords)
numWordsVocab=len(aliceVocab)
print("Number of different words in the book: ",numWordsVocab)
print("In the average each word is used %2.2f times"%(float(numWordsAll)/numWordsVocab))
Number of words in the book: 27341
Number of different words in the book: 2583
In the average each word is used 10.58 times
1.1.5.5. Determine Frequency of each word¶
wordFrequencies={}
for word in aliceVocab:
wordFrequencies[word]=aliceWords.count(word)
Sort the word-frequency dictionary according to decreasing word-frequency.
for word in list(wordFrequencies.keys())[:80]:
print(word, wordFrequencies[word])
drop 1
1
drunk 2
rose 4
welcome 1
frightened 7
dinah 14
inches 6
smoke 1
story 8
done 15
prove 1
delightful 2
lobsters 6
stretched 2
front 2
chain 1
contemptuous 1
direction 5
become 5
sand 1
piece 6
onions 1
trims 1
curious 19
alarm 2
coming 9
grunt 1
hard 8
saying 15
comfort 1
farmer 1
window 8
dropped 5
beautifully 2
digging 4
so 151
orange 1
yelp 1
settling 1
told 6
however 20
far 13
smallest 2
purpose 1
neighbouring 1
arms 6
livery 3
ours 1
knife 3
neck 7
anywhere 1
fit 3
furious 1
to 730
quietly 5
croqueting 1
uglification 2
feared 1
memorandum 1
playing 2
not 145
beasts 2
poky 1
school 6
cheerfully 1
ready 8
beloved 1
height 5
toss 1
hurt 3
skirt 1
sitting 10
doubtful 2
lasted 2
thinking 11
chance 4
shouting 2
seven 6
whiskers 3
print("40 most frequent words:\n")
for w in sorted(wordFrequencies, key=wordFrequencies.get, reverse=True)[:40]:
print(w, wordFrequencies[w])
40 most frequent words:
the 1635
and 872
to 730
a 630
it 593
she 552
i 543
of 513
said 461
you 409
alice 397
in 366
was 356
that 316
as 263
her 246
t 218
at 211
s 200
on 194
all 182
with 178
had 177
but 170
they 153
for 153
so 151
be 148
not 145
very 144
what 140
this 133
little 128
he 125
out 118
is 108
one 103
down 102
up 100
there 99
1.1.5.6. Optimization by stop-word removal¶
Stopwords are words, with low information content, such as determiners (the, a, …), conjunctions (and, or, …), prepositions (in, on, over, …) and so on. For typical information retrieval tasks stopwords are usually ignored. In the code snippet below, a stopword-list from NLTK is applied in order to remove these non-relevant words from the document-word lists. NLTK provides stopwordlists for many different languages. Since our text is written in English, we apply the English stopwordlist:
from nltk.corpus import stopwords
stopwordlist=stopwords.words('english')
aliceWords = [word.lower() for word in re.split(r"[\s.,;´`:'()!?\"-]+", rawAlice)
if word.lower() not in stopwordlist]
numWordsAll=len(aliceWords)
print("Number of words in the book: ",numWordsAll)
aliceVocab = set(aliceWords)
numWordsVocab=len(aliceVocab)
print("Number of different words in the book: ",numWordsVocab)
#print("In the average each word is used %2.2f times"%(float(numWordsAll)/numWordsVocab))
Number of words in the book: 12283
Number of different words in the book: 2437
Generate the dictionary for the cleaned text and display it in an ordered form:
wordFrequencies={}
for word in aliceVocab:
wordFrequencies[word]=aliceWords.count(word)
print("40 most frequent words:\n")
for w in sorted(wordFrequencies, key=wordFrequencies.get, reverse=True)[:40]:
print(w, wordFrequencies[w])
40 most frequent words:
said 461
alice 397
little 128
one 103
know 88
like 85
would 83
went 82
could 77
queen 75
thought 74
time 71
see 68
king 63
well 63
* 60
turtle 58
began 58
way 57
hatter 56
quite 55
mock 55
gryphon 54
think 53
say 52
first 51
rabbit 51
go 50
head 50
much 50
thing 49
voice 48
never 48
get 46
oh 45
looked 45
come 45
got 45
mouse 44
must 44
Another option to calculate the word frequencies in an ordered manner is to apply the nltk-class FreqDist.
%matplotlib inline
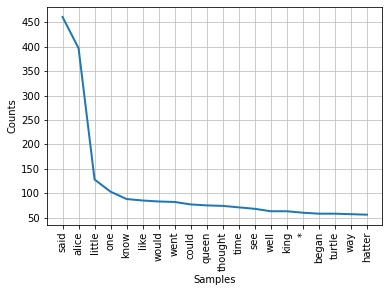
fd=nltk.FreqDist(aliceWords)
print(fd.most_common(20))
fd.plot(20)
[('said', 461), ('alice', 397), ('little', 128), ('one', 103), ('know', 88), ('like', 85), ('would', 83), ('went', 82), ('could', 77), ('queen', 75), ('thought', 74), ('time', 71), ('see', 68), ('well', 63), ('king', 63), ('*', 60), ('began', 58), ('turtle', 58), ('way', 57), ('hatter', 56)]
<AxesSubplot:xlabel='Samples', ylabel='Counts'>